
🐼 Pandas: Filtrar datasets, agrupar y visualización básica#
🛳️ Dataset Titanic#
El dataset Titanic es uno de los más conocidos en el mundo de la ciencia de datos y aprendizaje automático. Fue creado a partir de los datos de pasajeros del famoso transatlántico RMS Titanic, que se hundió en su viaje inaugural en abril de 1912 tras chocar contra un iceberg.
El objetivo clásico al trabajar con este dataset es predecir si un pasajero sobrevivió o no, en base a diferentes características como clase, edad, sexo, etc. Es ideal para practicar tareas de limpieza, visualización, modelado y análisis exploratorio de datos.

📄 Descripción de las columnas del dataset#
Columna |
Descripción |
|---|---|
PassengerId |
ID único para cada pasajero |
Survived |
Indicador de supervivencia: |
Pclass |
Clase del pasajero (1ra, 2da o 3ra clase) |
Name |
Nombre completo del pasajero (a menudo incluye título como Mr., Mrs., etc.) |
Sex |
Sexo del pasajero ( |
Age |
Edad del pasajero en años. Puede contener valores nulos |
SibSp |
Número de hermanos o cónyuges que viajaban con el pasajero |
Parch |
Número de padres o hijos que viajaban con el pasajero |
Ticket |
Número del boleto |
Fare |
Tarifa pagada por el boleto |
Cabin |
Cabina del pasajero (muchas veces está vacía) |
Embarked |
Puerto de embarque: |
Embarking_Date |
Fecha en la que se embarcó el pasajero. |
🐼 Práctica exploración y limpieza de datos:#
Explora el dataset Titanic:
Tamaño, estructura
Tipos de datos que contiene
Resumen estadístico
Valores únicos por columna
Visualiza 3 columnas con .plot()
Limpieza y ajustes:
¿Coinciden los tipos de datos con la información de cada columna?
¿Cuantas nulos hay en cada columna y en todo el dataset?
¿Cual es la mejor forma de manejar los nulos de cada columna?
Limpia los nulos de 3 columnas como mejor lo decidas, eliminacion, o imputación
¿Cuantos duplicados hay en el dataset? Eliminalos.
import pandas as pd
# Cargar el DataFrame desde un archivo CSV
url='https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/titanic_with_dates.csv'
df = pd.read_csv(url)
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1912-04-10T12:14:08Z |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1912-04-10T19:07:26Z |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1912-04-10T16:15:48Z |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1912-04-10T13:26:46Z |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1912-04-10T17:31:29Z |
🐼 Pandas: Filtrar datasets, agrupar y visualización básica (teoría)#
🎯 Objetivo del bloque#
Aprender a seleccionar subconjuntos de datos, resumirlos por grupos y comunicar hallazgos con visualizaciones simples.
1) 🔎 Filtrar datasets (selección de datos)#
Filtrar es quedarte con una parte del dataset según un criterio. Se usa para:
analizar un segmento específico (por ejemplo, un país, un producto, una cohorte),
excluir registros inválidos o fuera de alcance,
comparar grupos (A vs B) usando reglas consistentes.
Conceptos clave:
Filtrado por condiciones: seleccionar filas que cumplan una regla (igualdad, rangos, pertenencia a una lista, combinaciones).
Combinación de condiciones: unir reglas con lógica (y / o / no).
Filtrado por columnas: quedarte solo con las variables necesarias para el análisis (reduce ruido y errores).
Filtrado por fechas: seleccionar por intervalos temporales; requiere que las fechas estén bien interpretadas como fechas (no como texto).
Evitar “filtros que mienten”: si hay nulos, categorías inconsistentes o tipos errados, el filtro puede excluir o incluir mal (por eso se explora y limpia antes).
Resultado esperado: un dataset más pequeño y relevante, listo para calcular métricas o construir tablas resumen.
# Filtro por una condición
adultos = df[df["Age"] >= 18]
display(adultos.head())
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1912-04-10T12:14:08Z |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1912-04-10T19:07:26Z |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1912-04-10T16:15:48Z |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1912-04-10T13:26:46Z |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1912-04-10T17:31:29Z |
# Filtro multiples condiciones
fem_adultos = df[(df["Age"] >= 18) & (df["Sex"] == "female")]
display(fem_adultos.head())
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1912-04-10T19:07:26Z |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1912-04-10T16:15:48Z |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1912-04-10T13:26:46Z |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S | 1912-04-10T15:16:49Z |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S | 1912-04-10T14:58:44Z |
#Filtrar por lista de valores
clase_1_2 = df[df["Pclass"].isin([1, 2])]
display(clase_1_2.head())
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1912-04-10T19:07:26Z |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1912-04-10T13:26:46Z |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S | 1912-04-10T15:47:09Z |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C | 1912-04-10T19:08:11Z |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S | 1912-04-10T14:58:44Z |
#Filtrar por valores nulos
nulos_age = df[df["Age"].isnull()]
display(nulos_age.head())
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 1912-04-11T11:40:07Z |
| 17 | 18 | 1 | 2 | Williams, Mr. Charles Eugene | male | NaN | 0 | 0 | 244373 | 13.0000 | NaN | S | 1912-04-10T14:19:48Z |
| 19 | 20 | 1 | 3 | Masselmani, Mrs. Fatima | female | NaN | 0 | 0 | 2649 | 7.2250 | NaN | C | 1912-04-10T18:36:32Z |
| 26 | 27 | 0 | 3 | Emir, Mr. Farred Chehab | male | NaN | 0 | 0 | 2631 | 7.2250 | NaN | C | 1912-04-10T19:40:54Z |
| 28 | 29 | 1 | 3 | O'Dwyer, Miss. Ellen "Nellie" | female | NaN | 0 | 0 | 330959 | 7.8792 | NaN | Q | 1912-04-11T11:46:17Z |
#Filtrar por rango de edad
rango_edad = df[df["Age"].between(30, 40)]
display(rango_edad.head())
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Embarked_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1912-04-10T19:07:26Z |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1912-04-10T13:26:46Z |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1912-04-10T17:31:29Z |
| 13 | 14 | 0 | 3 | Andersson, Mr. Anders Johan | male | 39.0 | 1 | 5 | 347082 | 31.2750 | NaN | S | 1912-04-10T16:00:15Z |
| 18 | 19 | 0 | 3 | Vander Planke, Mrs. Julius (Emelia Maria Vande... | female | 31.0 | 1 | 0 | 345763 | 18.0000 | NaN | S | 1912-04-10T12:36:57Z |
# Filtrar por filas y columnas específicas
subset = df.loc[df["Age"] >= 18, ["Name", "Age", "Sex"]]
display(subset.head())
| Name | Age | Sex | |
|---|---|---|---|
| 0 | Braund, Mr. Owen Harris | 22.0 | male |
| 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | female |
| 2 | Heikkinen, Miss. Laina | 26.0 | female |
| 3 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | female |
| 4 | Allen, Mr. William Henry | 35.0 | male |
2) 🧩 Agrupar datos (resúmenes por categoría)#
Agrupar es convertir datos “a nivel registro” en información agregada por una o varias categorías (por ejemplo, por ciudad, mes, canal, tipo de cliente). Es esencial para responder preguntas de negocio.
Conceptos clave:
Clave(s) de agrupación: columnas que definen los grupos (una o varias).
Ejemplo conceptual: agrupar porciudadymescrea un grupo por cada combinación ciudad–mes.Agregaciones: operaciones que resumen cada grupo (conteo, suma, promedio, mediana, mínimo/máximo, porcentajes, etc.).
Métricas derivadas: después de agrupar, a menudo se calculan ratios (por ejemplo, tasa, margen, participación, crecimiento).
Orden y legibilidad: un buen resumen suele incluir ordenamiento por una métrica clave y un formato claro.
Granularidad: agrupar demasiado fino (muchas categorías) produce ruido; agrupar demasiado grueso oculta patrones. La clave es elegir el nivel correcto para la pregunta.
Resultado esperado: una tabla resumen que responde “qué pasa” por segmento.

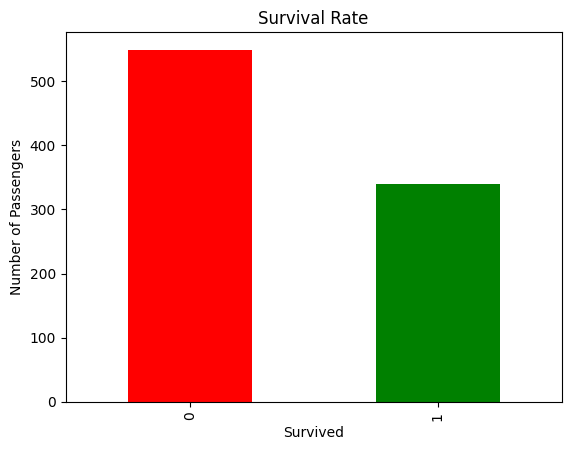
#Supervivencia
survival_rate = df.groupby(['Survived'])['PassengerId'].count().reset_index()
display(survival_rate)
| Survived | PassengerId | |
|---|---|---|
| 0 | 0 | 549 |
| 1 | 1 | 340 |
#Visualización de la tasa de supervivencia
survival_rate.plot(kind='bar', x='Survived', y='PassengerId', title='Survival Rate', legend=False, ylabel='Number of Passengers', xlabel='Survived', color=['red', 'green'])
<Axes: title={'center': 'Survival Rate'}, xlabel='Survived', ylabel='Number of Passengers'>
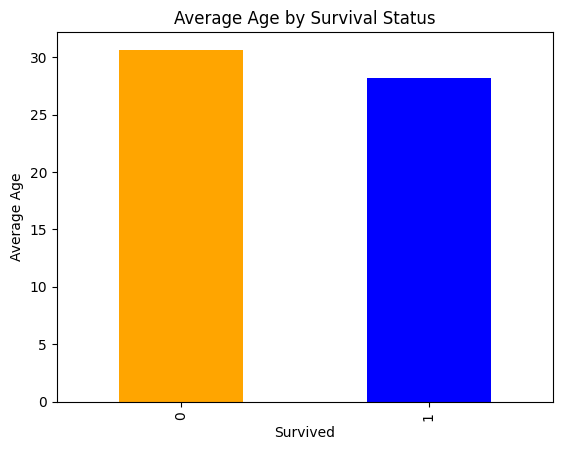
#survival age
survival_age = df.groupby(['Survived'])['Age'].mean().reset_index()
display(survival_age)
| Survived | Age | |
|---|---|---|
| 0 | 0 | 30.626179 |
| 1 | 1 | 28.193299 |
#plot
survival_age.plot(kind='bar', x='Survived', y='Age', title='Average Age by Survival Status', legend=False, ylabel='Average Age', xlabel='Survived', color=['orange', 'blue'])
<Axes: title={'center': 'Average Age by Survival Status'}, xlabel='Survived', ylabel='Average Age'>
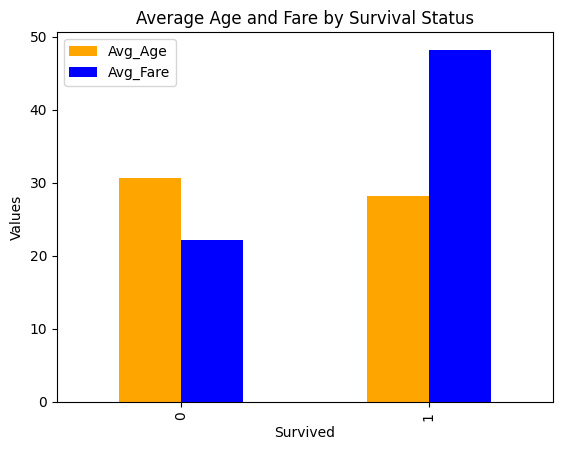
# survival avg age and avg fare
survival_stats = df.groupby(['Survived'])[['Age', 'Fare']].mean().reset_index()
#ajuste de nombres de columnas
survival_stats.columns = ['Survived', 'Avg_Age', 'Avg_Fare']
display(survival_stats)
| Survived | Avg_Age | Avg_Fare | |
|---|---|---|---|
| 0 | 0 | 30.626179 | 22.117887 |
| 1 | 1 | 28.193299 | 48.209498 |
#visualización
survival_stats.plot(kind='bar', x='Survived', y=['Avg_Age', 'Avg_Fare'], title='Average Age and Fare by Survival Status', ylabel='Values', xlabel='Survived', color=['orange', 'blue'])
<Axes: title={'center': 'Average Age and Fare by Survival Status'}, xlabel='Survived', ylabel='Values'>
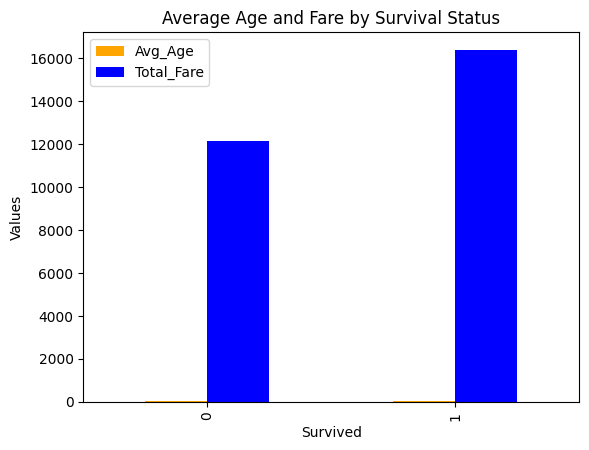
#survival avg age and sum fare
survival_stats_sum = df.groupby(['Survived'])[['Age', 'Fare']].agg(
Avg_Age = ('Age', 'mean'),
Total_Fare = ('Fare', 'sum')
).reset_index()
display(survival_stats_sum)
| Survived | Avg_Age | Total_Fare | |
|---|---|---|---|
| 0 | 0 | 30.626179 | 12142.7199 |
| 1 | 1 | 28.193299 | 16391.2294 |
#visualización
survival_stats_sum.plot(kind='bar', x='Survived', y=['Avg_Age', 'Total_Fare'], title='Average Age and Fare by Survival Status', ylabel='Values', xlabel='Survived', color=['orange', 'blue'])
<Axes: title={'center': 'Average Age and Fare by Survival Status'}, xlabel='Survived', ylabel='Values'>
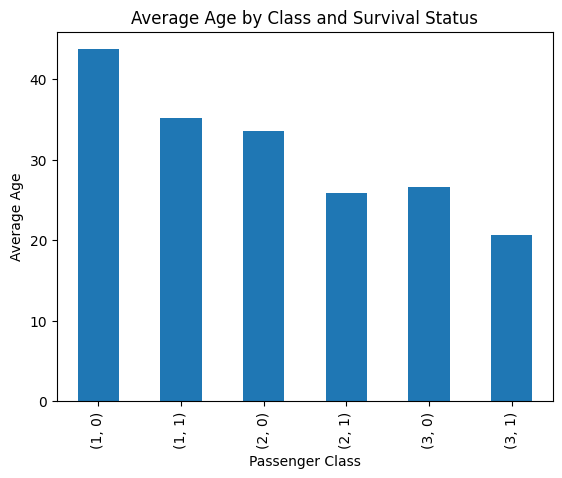
# Edad promedio por clase y supervivencia
survival_by_class = df.groupby(['Pclass', 'Survived'])['Age'].mean()
display(survival_by_class)
Pclass Survived
1 0 43.695312
1 35.124333
2 0 33.544444
1 25.901566
3 0 26.555556
1 20.646118
Name: Age, dtype: float64
survival_by_class.plot(kind='bar',y='Age', title='Average Age by Class and Survival Status', ylabel='Average Age', xlabel='Passenger Class')
<Axes: title={'center': 'Average Age by Class and Survival Status'}, xlabel='Passenger Class', ylabel='Average Age'>
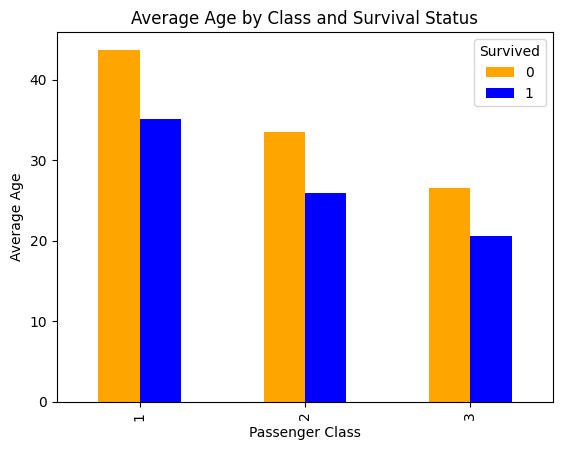
survival_by_class = df.groupby(['Pclass', 'Survived'])['Age'].mean().unstack()
display(survival_by_class)
| Survived | 0 | 1 |
|---|---|---|
| Pclass | ||
| 1 | 43.695312 | 35.124333 |
| 2 | 33.544444 | 25.901566 |
| 3 | 26.555556 | 20.646118 |
survival_by_class.plot(kind='bar', title='Average Age by Class and Survival Status', ylabel='Average Age', xlabel='Passenger Class', color=['orange', 'blue'])
<Axes: title={'center': 'Average Age by Class and Survival Status'}, xlabel='Passenger Class', ylabel='Average Age'>
Ahora tu#
Genera 3 agrupaciones que respondan a una pregunta sobre el dataset