
Sprint 1 - Introducción a tu futura profesión#
Clase teórica

Introducción#
En esta sesión conocerás el rol del Data Analyst (DA), su proceso de trabajo y cómo colabora con otros perfiles de datos para generar valor de negocio. Usaremos el archivo taylor_swift_da_intro.xlsx como hilo conductor para aterrizar conceptos.
¿Por qué este caso?
Conecta con cultura pop (Taylor Swift) y métricas de streaming/videos.
El archivo contiene problemas de calidad realistas (fechas mixtas, booleanos variados, duplicados, números con símbolos), útiles para comprender el trabajo del DA.
Objetivos de aprendizaje#
Al finalizar la sesión podrás:
Explicar qué hace un Data Analyst y y diferenciarlo de otros roles (DS, DE, BI, PM).
Describir el proceso de trabajo del DA desde una pregunta de negocio hasta una entrega final.
Identificar a los stakeholders clave y los entregables que se esperan de un DA.
Reconocer niveles de seniority y las expectativas asociadas en la carrera de datos.
Aplicar estos conceptos al caso de Taylor Swift utilizando el archivo como ejemplo teórico.
Agenda#
Rol del DA (qué hace y qué no hace)
Principales roles en el mundo de datos y cómo colaboran
Proceso de trabajo del DA (de la pregunta de negocio a la entrega)
DA en distintos tipos de organizaciones
Tipos de seniority y expectativas
Aplicación guiada
Caso conceptual de Taylor Swift: mapping de conceptos
El rol del Analista de Datos#
El Data Analyst traduce preguntas de negocio en respuestas basadas en datos y entregables accionables (reportes, visualizaciones, checks de calidad, recomendaciones).
Responsabilidades nucleares:
Entender el contexto/objetivos del stakeholder y definir métricas relevantes.
Obtener datos de fuentes diversas (spreadsheets, CSVs, conectores).
Limpiar/preprocesar (tipos, duplicados, nulos, estandarización).
Explorar/calcular (resúmenes, segmentaciones, tendencias simples).
Comunicar con claridad (gráficos de barras/líneas, narrativa).
Documentar cambios y su racional (bitácora o
change_log).
Límites típicos del DA (y cuándo escalar):
Modelos ML experimentales → DS/ML.
Pipelines/infra de datos → DE.
Modelado semántico/tableros escalables → BI/Analytics Engineer.
Pista: “¿Qué canciones priorizar para la próxima campaña/gira?”
Un mundo lleno de herramientas#
Python como recurso principal: Pronto nos introduciremos a la programación con Python.
¿De donde provienen los datos?: Podemos conseguir datos de distintas fuentes: web scraping, bases de datos, o bien, en archivos planos como libros Excel o CSV.
Tus primeros pasos: Empezaremos realizando exploraciones de datos en archivos planos, luego pasaremos a hacer la exploración en bases de datos (Sprint 3) y posterior a eso, exploraremos el mismo proceso en Python (Sprint 5).
DA en diferentes tipos de organizaciones#
Startup: rol generalista (limpieza → insight → slide). Velocidad > formalización.
Mid-size: especialización moderada; DA trabaja con BI/DE; procesos básicos de gobierno.
Enterprise: clara división de funciones, compliance, estándares estrictos, data governance.
Implicaciones para el DA:
En entornos pequeños, el DA diseña flujos de extremo a extremo.
En empresas grandes, el foco es claridad, trazabilidad y hand-off impecable.
Tipos de Seniority#
Junior: limpieza y métricas básicas; documentación guiada; foco en best practices.
Mid: autonomía en limpieza/comunicación; propone KPIs y flujos de trabajo.
Senior: define estándares, lidera entregas complejas y coordinación con otros roles.
Lead/Manager: visión, priorización de iniciativas, relación con negocio.
Autoevaluación (rápida):
¿Puedo explicar mi decisión metodológica a un stakeholder no técnico?
¿Mis archivos se entienden sin mí (nombres, notas,
change_log)?¿Sé cuándo escalar a BI/DE/DS?
Work Process (de la pregunta a la entrega)#
Un flujo práctico y repetible para el DA:
Descubrir el problema
¿Qué decisión se tomará? ¿Qué KPI importa? ¿Para quién?
Auditar fuentes
¿Qué hay en
raw_songs/raw_albums? ¿Qué issues evidenciadata_dictionary?
Limpieza y estandarización
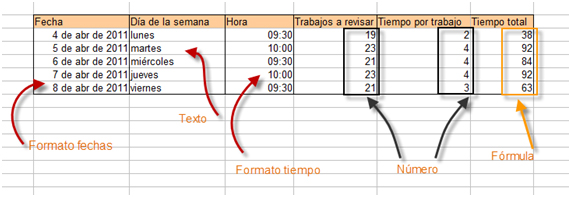
Fechas a un estándar (ISO 8601), booleanos a TRUE/FALSE, números sin símbolos, remover duplicados.
Cálculo & EDA
Métricas simples (SUM, COUNT, AVERAGE, MIN, MAX), segmentaciones por álbum/era.
Visualización & narrativa
Gráfico (barra/línea). ¿Qué significa? ¿Qué acción sugiere?
Handoff & documentación
Archivo ordenado (nombres de hojas, formato),
change_logcon pasos y ejemplos antes/después.
Relación con OSEMN: Obtain (fuentes) → Scrub (limpieza) → Explore (EDA) → Model (agregados/segmentos) → iNterpret (insights/decisión).
Sesión práctica#
Caso conceptual de Taylor Swift
Aplicación conceptual al caso Taylor Swift#

¿Conoces a Taylor Swift?
Contexto: taylor_swift_da_intro.xlsx → hojas raw_songs, raw_albums, data_dictionary, change_log, summary_template.
Paso A — Inspección y mapeo
Revisa
data_dictionarypara entender tipos esperados y definiciones.Lista de riesgos: fechas mixtas, booleanos no estándar (Yes/No/1/0), separación inconsistente en
Writers, números con símbolos/comas, duplicados.
Paso B — Reglas de limpieza (definir antes de tocar datos)
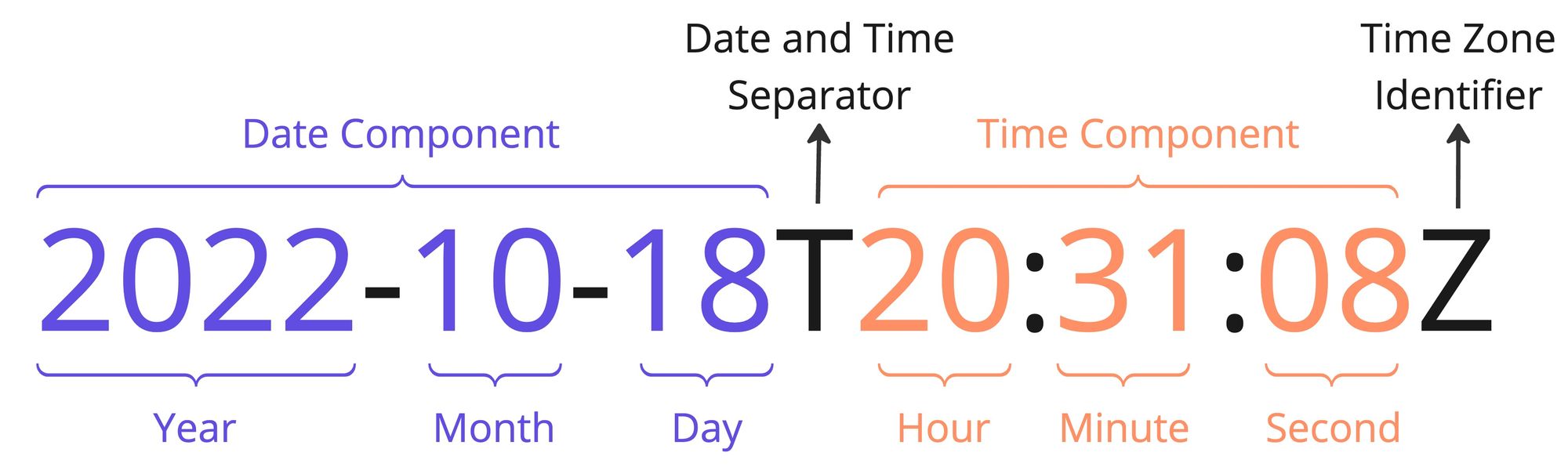
Fechas →
YYYY-MM-DD.Booleanos →
{TRUE, FALSE}únicamente.Números → sin símbolos, sin espacios; separador decimal consistente.
Writers→ separador único (p. ej.,;).Duplicados → criterio: columnas clave
Song+Album+Release Date(definir).
Paso C — Documentación (change_log)
Cada cambio = fila con quién/cuándo/qué + ejemplo antes/después.
Paso D — Métricas base (summary_template)
Total Tracks,Unique Albums,Average Streams,Average Views,Explicit TRUE.Añadir un gráfico simple (barra/línea) para comunicar.
Paso E — Narrativa breve
“Top canciones por streams promedio”, “outliers”, “recomendación de foco para campaña/artista/tour”.
Ejercicio#
Archivo base:
taylor_swift_da_intro.xlsxlink
Objetivo: practicar limpieza y exploración ligera solo en Google Sheets (sin programar). Trabaja SIEMPRE sobre una copia limpia.
Ejercicio 1 — Preparación del archivo#
Sube el .xlsx a Google Drive → clic derecho → Abrir con → Hojas de cálculo de Google.
Duplica la hoja
raw_songscomoclean_songs(clic derecho en pestaña → Duplicar). Nunca editesraw_songs.Congela la fila de encabezados: Ver → Congelar → 1 fila.
Ajusta anchos (doble clic en separador de columna) y revisa que los encabezados sean legibles.
Renombra hojas si hace falta (p.ej.,
clean_*,summary_*).En la hoja
change_log, agrega tu primera fila: “Creé hoja clean_songs a partir de raw_songs” (fecha/hora opcional).
Entrega esperada: archivo ordenado con estructura clara.
¿Por qué no trabajar sobre los datos base? Para preservar el insumo original y poder repetir/validar cambios sin riesgo.
Ejercicio 2 — Estandarizar fechas y booleanos#
A) Fechas (Release Date, Date Added) a formato YYYY-MM-DD:
Selecciona la(s) columna(s) de fecha → Formato → Número → Fecha.
Si se importaron como texto, usa una columna auxiliar en
clean_songs:=IFERROR( DATE(VALUE(RIGHT(C2,4)), VALUE(LEFT(C2,FIND("/",C2)-1)), VALUE(MID(C2,FIND("/",C2)+1,FIND("/",C2, FIND("/",C2)+1)-FIND("/",C2)-1))), IFERROR( DATE(VALUE("20"&RIGHT(C2,2)), VALUE(MID(C2,4,2)), VALUE(LEFT(C2,2))), "") )
Ajusta
C2al nombre/columna real. Copia hacia abajo, Pegar especial → Solo valores y reemplaza la original.
B) Booleanos (Explicit) a TRUE/FALSE:
En columna auxiliar (p.ej., junto a
Explicit):=IF(REGEXMATCH(LOWER(C2), "^(y|yes|1|true)$"), TRUE, IF(REGEXMATCH(LOWER(C2), "^(n|no|0|false)$"), FALSE,""))
o si prefieres:
=IF(OR(C2=1; C2="1"; LOWER(C2)="y"; LOWER(C2)="yes"; LOWER(C2)="true"), TRUE, IF(OR(C2=0; C2="0"; LOWER(C2)="n"; LOWER(C2)="no"; LOWER(C2)="false"), FALSE,""))
Copia hacia abajo → Pegar especial → Solo valores → reemplaza la columna original.
Entrega esperada: fechas y booleanos consistentes, documentados en change_log (qué hiciste y por qué).
Ejercicio 3 — Números y separadores#
Objetivo: limpiar Spotify Streams (M) y YouTube Views (M) para que queden como número (sin símbolos/comas/espacios).
Quitar símbolos con Buscar y reemplazar (Ctrl/Cmd + H):
Buscar:
$→ Reemplazar: (vacío) → Reemplazar todo.Repite con
€, espacios,si corresponde.
Si aún quedan textos, crea columna auxiliar con fórmula y luego pega valores:
=VALUE(REGEXREPLACE(REGEXREPLACE(A2,"[^\d\.\,\-]",""),",",""))
Explicación: elimina todo lo que no sea dígito/punto/coma/signo; luego cambia comas por puntos y convierte a número.
Verifica con Datos → Crear filtro y ordena de mayor a menor para confirmar que se comportan como números.
Entrega esperada: columnas numéricas limpias (tipo número), con nota en change_log.
¿Por qué no escribir manualmente puntos/comas? Porque es propenso a error y no escala; además, pierde trazabilidad en
change_log.
Ejercicio 4 — Duplicados y separadores de texto#
Detectar/eliminar duplicados según regla (Song + Album + Release Date):
Selecciona el rango de datos en
clean_songs→ Datos → Limpieza de datos → Quitar duplicados.Marca columnas de la regla y confirma.
Unificar separador en
Writersa;:Editar → Buscar y reemplazar: reemplaza
,o/por;(repite según variantes detectadas).Alternativa con fórmula (columna auxiliar y luego pega valores):
=SUBSTITUTE(SUBSTITUTE(A2, ",", ";"), "/", ";")
Entrega esperada: sin duplicados y separador consistente en Writers.
Ejercicio 5 — Métricas y visualización#
Trabaja en la hoja summary_template (ya creada en el archivo base). Usa referencias a clean_songs:
Total Tracks (conteo de filas con nombre de canción en
clean_songs!A:A):=COUNTA(clean_songs!A2:A)
Unique Albums (contar distintos en
clean_songs!B:B):=COUNTA(UNIQUE(clean_songs!B2:B))
Average Spotify Streams (M) (columna numérica ya limpia, p.ej.,
clean_songs!F:F):=AVERAGE(clean_songs!F2:F)
Average YouTube Views (M) (p.ej.,
clean_songs!G:G):=AVERAGE(clean_songs!G2:G)
Tracks Marked Explicit (columna booleana en
clean_songs!H:H):=COUNTIF(clean_songs!H2:H, TRUE)
Gráfico de barras (top 5 por Streams o por Views):
En
clean_songs, Ordenar de mayor a menor por la métrica elegida.Seleccionar las 5 primeras filas (columna
Song+ columna métrica).Insertar → Gráfico → Tipo Barras. Ajusta títulos/etiquetas en el panel derecho.
Insights y recomendación: escribe 3 viñetas con hallazgos y 1 recomendación breve (p.ej., “enfocar promoción en álbum X por mayor streams promedio”).
Entrega esperada: summary_template completo + 1 gráfico simple + viñetas.
Ejercicio 6 — Handoff y checklist#
Revisa nombres de hojas y consistencia general.
Verifica que
change_logenumere los pasos clave (fechas, booleanos, limpieza numérica, duplicados, writers).Deja 2–3 preguntas para el stakeholder (suposiciones o limitaciones que encontraste).
Entrega esperada: archivo listo para compartir + 3 preguntas de seguimiento.
¿Qué aprendimos hoy?#
El DA es el puente entre preguntas de negocio y evidencia en datos.
Un proceso claro y trazable es tan importante como el resultado.
Siguientes Pasos#
Próxima sesión: profundizaremos en el ecosistema de datos y en el flujo de punta a punta.
Participación continua: asistir a Co-Learning y a Sprint Focus, y usar los canales de Discord para hacer preguntas.
Recordatorios: la grabación y recursos utilizados, se comparten al finalizar la sesión; en caso de necesitar apoyo adicional, agenda un 1:1.