
Sprint 7: Análisis estadístico para detectar patrones y outliers#
Distribuciones, histogramas, variabilidad y detección de outliers (IQR y Z-score)#
🎯 Objetivos de la sesión#
Al final de esta clase podrás:
Explicar qué es una distribución y cómo se interpreta un histograma.
Entender qué es la distribución normal y qué significa “normalidad” en análisis de datos.
Diferenciar medidas de tendencia central vs variabilidad.
Calcular e interpretar rango, IQR, varianza y desviación estándar.
Entender percentiles y cuartiles como “puntos de corte” de una distribución.
Detectar outliers con dos enfoques:
Rango intercuartílico (IQR)
Z-score
Decidir qué método usar según el tipo de distribución y el objetivo del análisis.
🧭 Agenda#
Distribuciones y forma
simétrica, sesgada, colas largas, multimodal
Histogramas: cómo leerlos
bins, densidad, forma, centro, dispersión
Variabilidad (20–30 min)
rango, IQR, varianza, desviación estándar
Cuartiles y percentiles
Q1, Q2, Q3; P90, P95
Outliers
IQR rule
Z-score
comparación, pros/cons
¿Qué es una distribución?#
Una distribución describe cómo se reparten los valores de una variable (por ejemplo: ingresos, tiempos de entrega, precios).
Cuando observas una distribución, analiza:
Centro: ¿dónde se concentra la mayoría? (media/mediana)
Dispersión: ¿qué tan “esparcidos” están los datos?
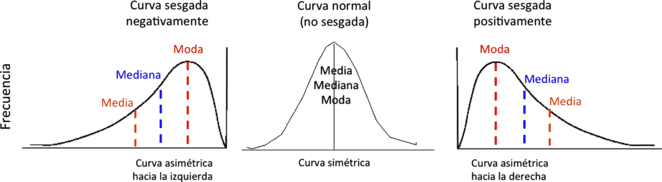
Forma:
Simétrica (valores equilibrados a ambos lados)
Sesgada a la derecha (cola larga hacia valores altos: ingresos, revenue)
Sesgada a la izquierda (cola hacia valores bajos: notas con “techo”)
Multimodal (varios picos: mezcla de grupos distintos)
Medidas de variabilidad (dispersión)#
Rango#
max - min
Simple, pero muy sensible a outliers.

Varianza y desviación estándar#
Varianza: promedio del cuadrado de la distancia a la media.
Desviación estándar (std): raíz de la varianza (misma unidad del dato).

Idea clave:
std grande = datos más dispersos
Advertencia:
media y std se afectan por outliers; por eso, para distribuciones sesgadas suelen ser menos estables.
Percentiles y cuartiles#
Percentil
P90: el 90% de los datos está por debajo.Cuartiles:
Q1= P25Q2= P50 (mediana)Q3= P75

IQR (rango intercuartílico)#
IQR = Q3 - Q1
Mide la dispersión del “centro” del 50% de los datos.

Distribución normal (gaussiana) y “normalidad”#
¿Qué es la distribución normal?#
La distribución normal (o gaussiana) es una distribución simétrica con forma de “campana”, donde:
La mayoría de valores se concentran alrededor del centro.
La frecuencia disminuye gradualmente hacia los extremos (colas).
En la normal ideal: media = mediana = moda.
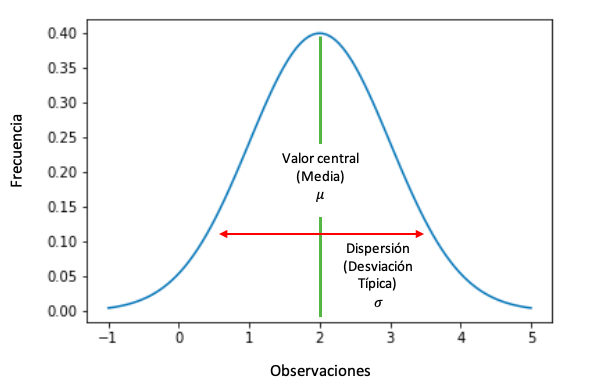
Se define por:
μ (mu): media (centro)
σ (sigma): desviación estándar (dispersión)
Intuición:
σ grande → campana “ancha” (más dispersión)
σ pequeña → campana “estrecha” (más concentración)
¿Qué significa “normalidad”?#
Normalidad es asumir (o verificar) que los datos se comportan aproximadamente como una normal.
Importa porque habilita interpretaciones y reglas útiles:
Regla 68–95–99.7 (aproximación):
~68% de valores dentro de ±1σ
~95% dentro de ±2σ
~99.7% dentro de ±3σ

Traducción práctica:
Si una variable es ~normal, un valor con
|z| > 3es raro → candidato a outlier.
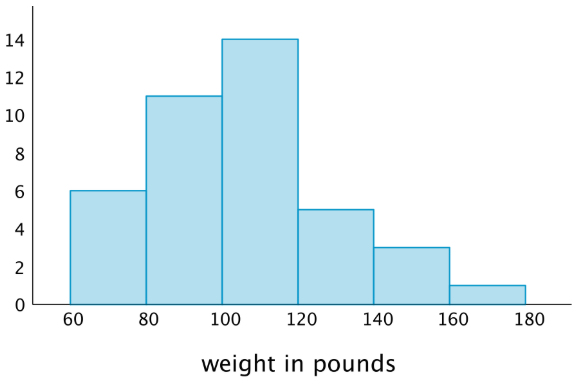
Histograma: cómo interpretarlo sin caer en la trampa de los bins#
Un histograma agrupa valores en intervalos (bins) y cuenta cuántos caen en cada uno.
Qué mirar:
Picos (modas): ¿hay uno o varios?
Colas: ¿hacia dónde se estira? (sesgo)
Huecos: posibles errores o subgrupos
Escala: un outlier puede “aplanar” el resto
Bins: cambiar bins puede cambiar la narrativa (sin cambiar los datos)

Regla práctica:
Si el histograma cambia mucho con bins distintos, complementa con boxplot y percentiles.
Detección de outliers#
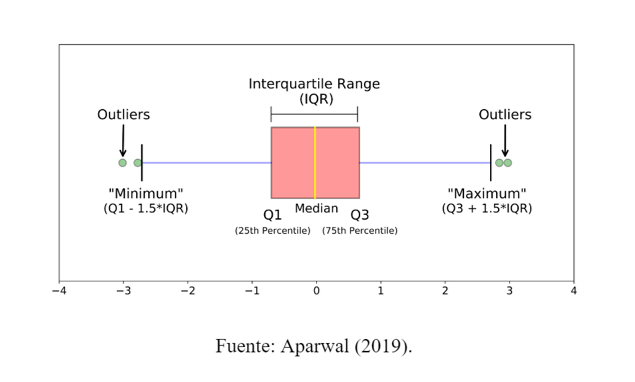
Método IQR (regla de Tukey)#
Calcula
Q1yQ3IQR = Q3 - Q1Límites:
Inferior:
Q1 - 1.5 * IQRSuperior:
Q3 + 1.5 * IQR
Fuera de límites → outlier
✅ Ventajas:
No asume normalidad
Robusto en distribuciones sesgadas
⚠️ Limitaciones:
En colas largas puede marcar muchos casos extremos reales
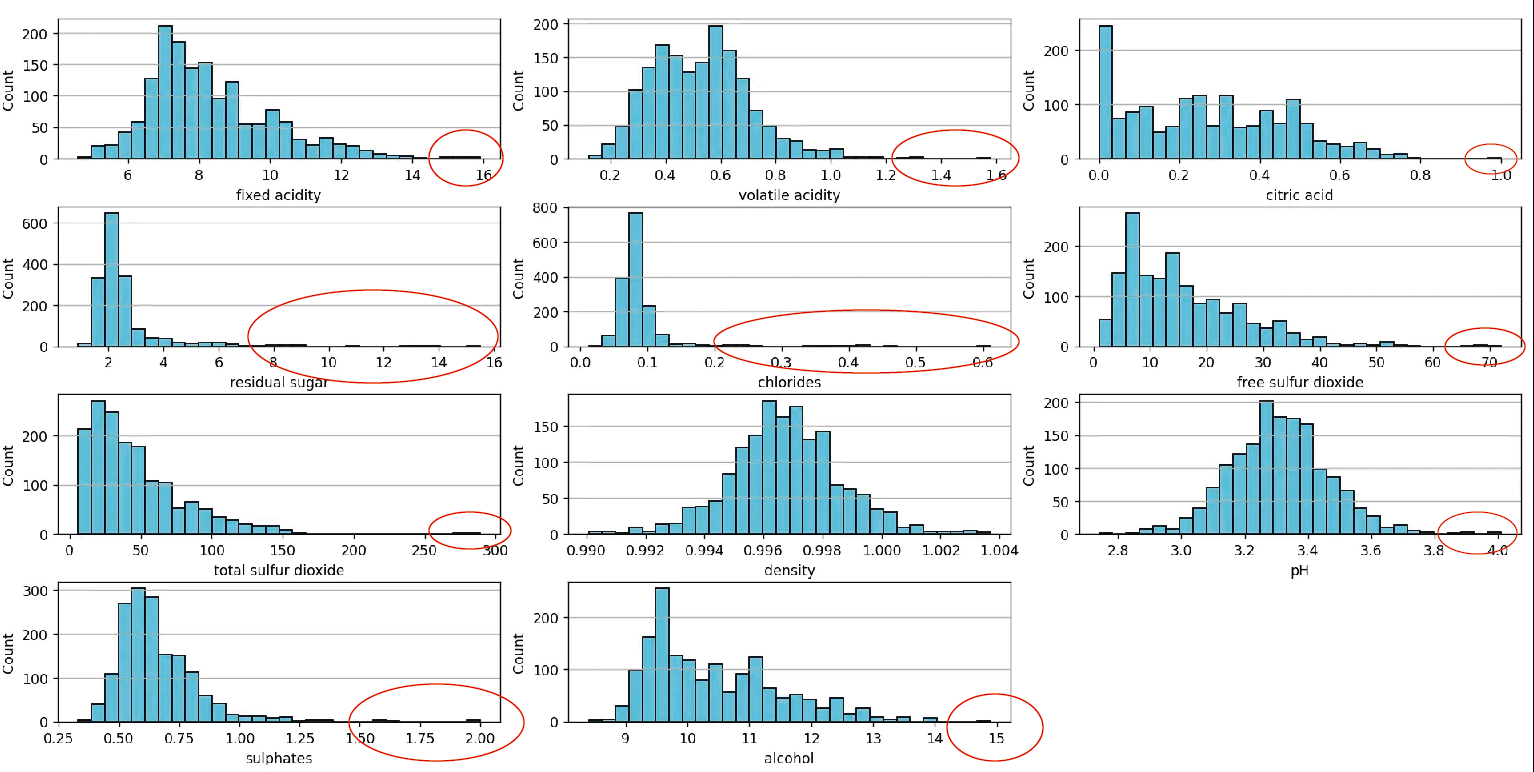 #
#
Método Z-score#
z = (x - mean) / std
Regla típica:
|z| > 3→ outlier fuerte (a veces> 2.5)
✅ Ventajas:
Muy interpretable si hay normalidad aproximada
⚠️ Limitaciones:
Outliers contaminan media y std (el outlier puede “camuflarse”)
En sesgo/colas largas suele fallar sin transformación
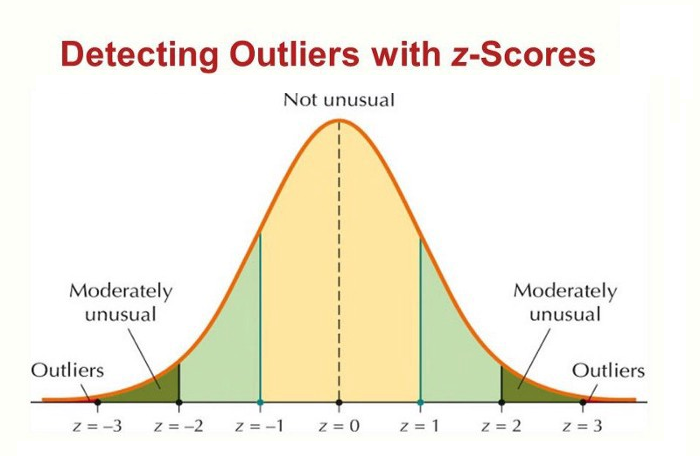
¿Cuál usar?#
Variable ~normal → Z-score puede funcionar bien.
Variable sesgada/cola larga → IQR suele ser más estable.
En negocio: antes de “limpiar”, decide si el outlier es error o caso extremo real (VIP, evento, fraude, etc.).
# Demostraciones de codigo
import pandas as pd
url='https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/diabetes.csv'
df = pd.read_csv(url)
df.head()
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
# Histogramas
import matplotlib.pyplot as plt
import seaborn as sns
df['Outcome']= df['Outcome'].astype('category')
for column in df.select_dtypes(include=['float64', 'int64']).columns:
plt.figure(figsize=(10, 6))
sns.histplot(df[column], bins=60, kde=True, color='violet')
plt.title(f'Histograma de {column}')
plt.xlabel(column)
plt.ylabel('Frecuencia')
plt.show()
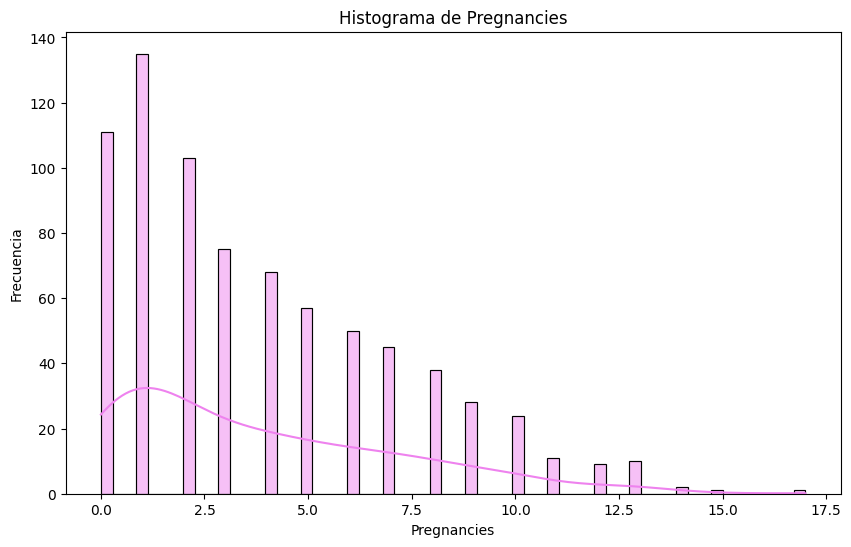
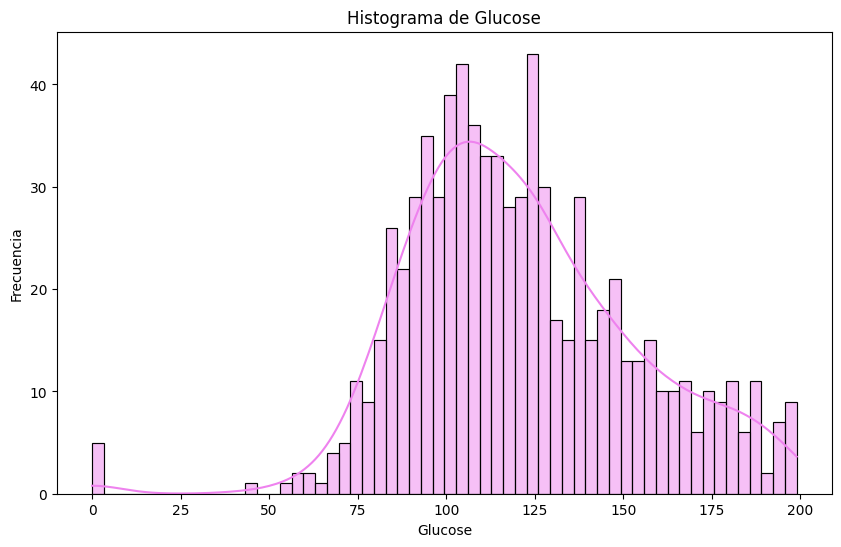
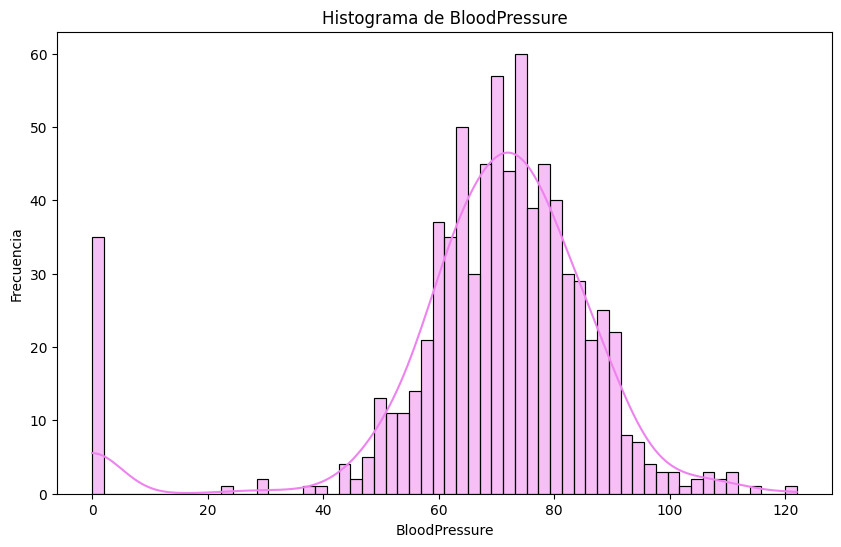
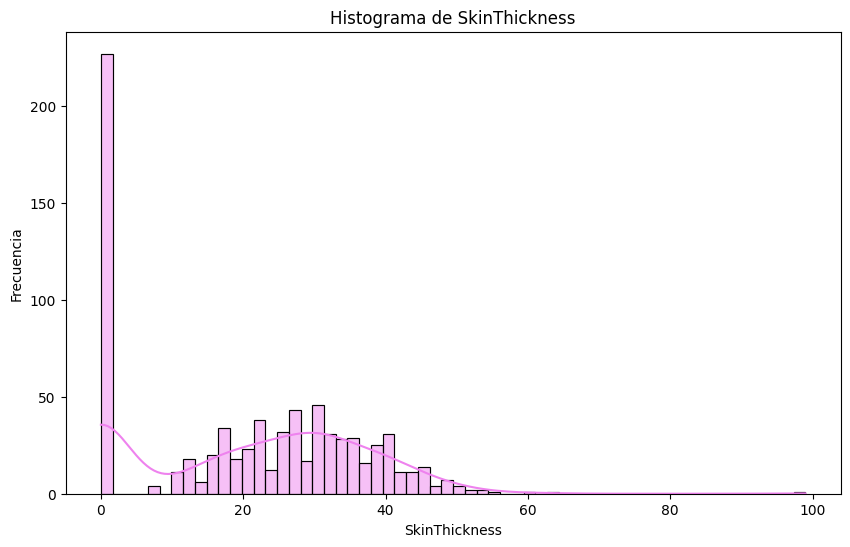
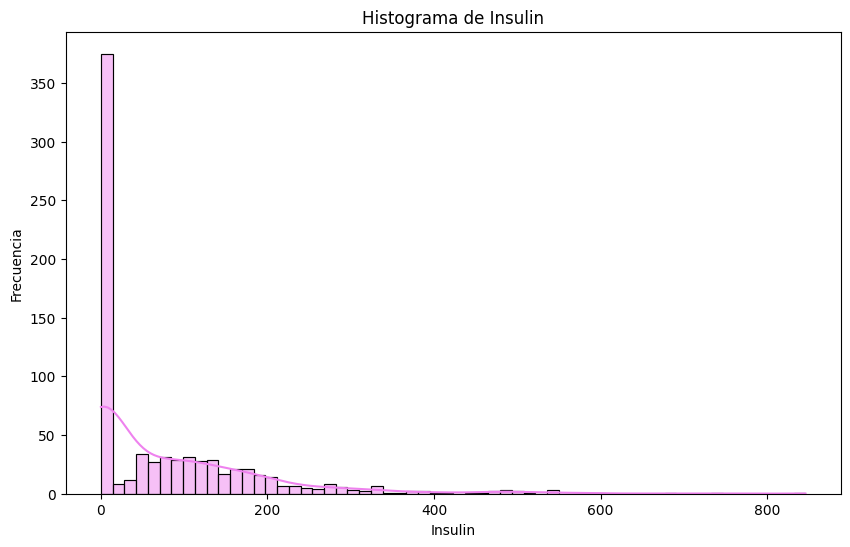
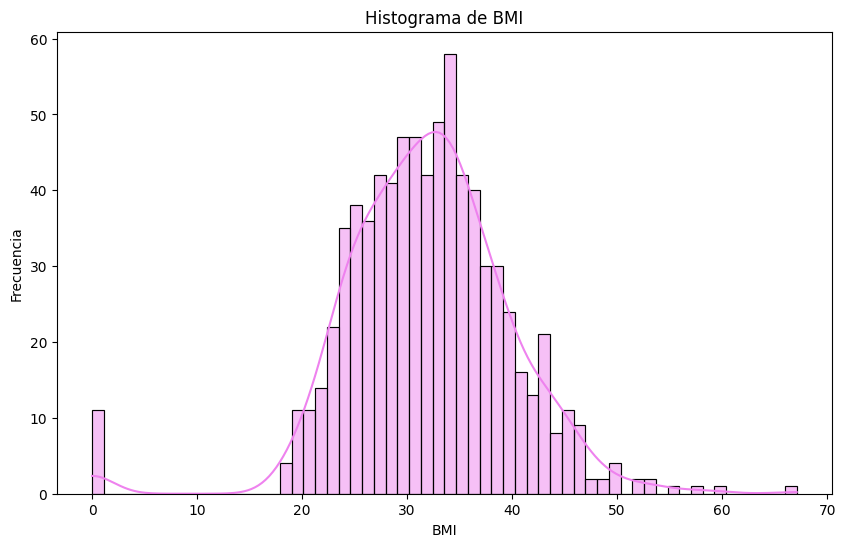
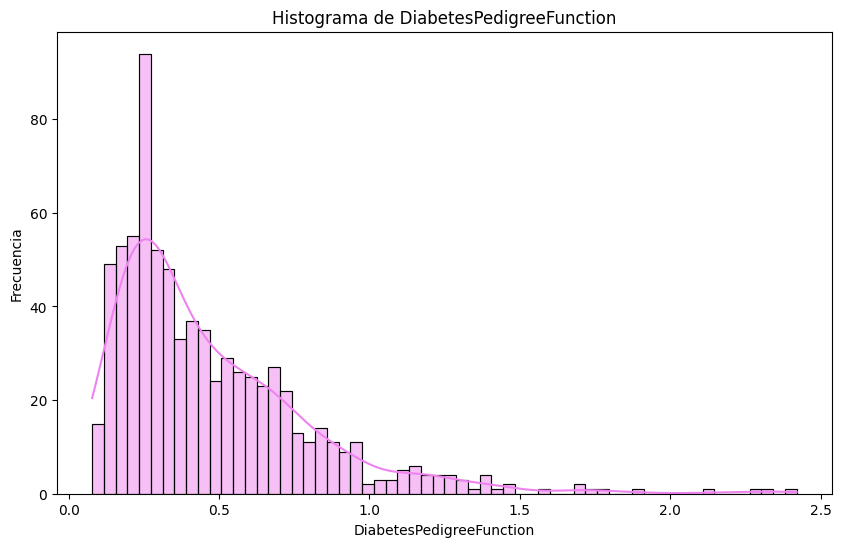
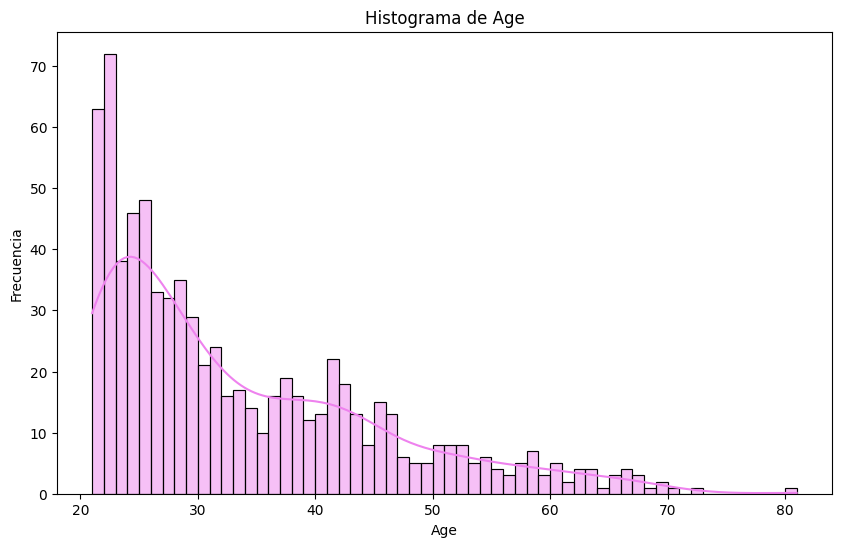
# Outliers en `pregnancies`. Metodo IQR
Q1 = df['Pregnancies'].quantile(0.25)
Q3 = df['Pregnancies'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['Pregnancies'] < lower_bound) | (df['Pregnancies'] > upper_bound)]
print("Outliers en 'Pregnancies':")
display(outliers)
Outliers en 'Pregnancies':
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 88 | 15 | 136 | 70 | 32 | 110 | 37.1 | 0.153 | 43 | 1 |
| 159 | 17 | 163 | 72 | 41 | 114 | 40.9 | 0.817 | 47 | 1 |
| 298 | 14 | 100 | 78 | 25 | 184 | 36.6 | 0.412 | 46 | 1 |
| 455 | 14 | 175 | 62 | 30 | 0 | 33.6 | 0.212 | 38 | 1 |
#Veamos un boxplot para visualizar los outliers
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['Pregnancies'], color='darkorange')
plt.title('Boxplot de Pregnancies')
plt.xlabel('Pregnancies')
Text(0.5, 0, 'Pregnancies')
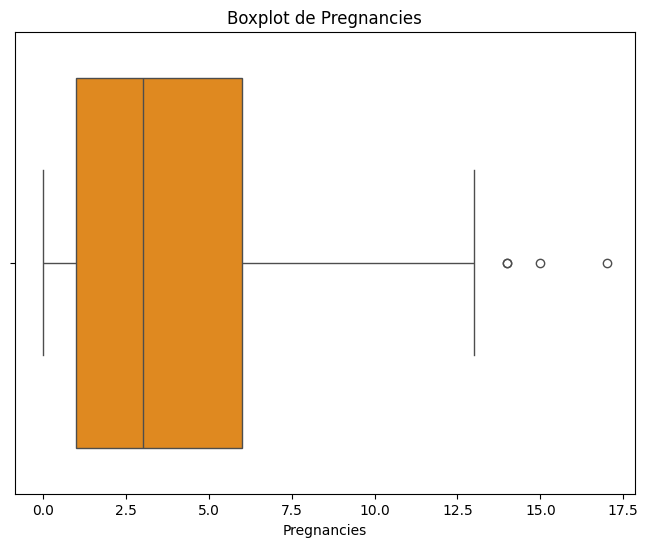
¿Que harías con estos datos
Son errores?
Son parte de la naturaleza del fenomeno?
Generan alguna alteración en las metricas o resultados de los estudios?
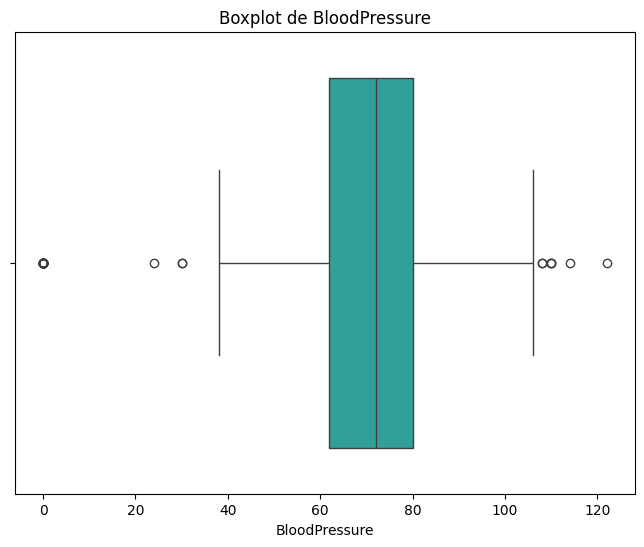
#Analizamos los outliers de `Blood pressure` usando el mismo metodo IQR
Q1_bp = df['BloodPressure'].quantile(0.25)
Q3_bp = df['BloodPressure'].quantile(0.75)
IQR_bp = Q3_bp - Q1_bp
lower_bound_bp = Q1_bp - 1.5 * IQR_bp
upper_bound_bp = Q3_bp + 1.5 * IQR_bp
outliers_bp = df[(df['BloodPressure'] < lower_bound_bp) | (df['BloodPressure'] > upper_bound_bp)]
print("Outliers en 'BloodPressure':")
display(outliers_bp)
Outliers en 'BloodPressure':
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 7 | 10 | 115 | 0 | 0 | 0 | 35.3 | 0.134 | 29 | 0 |
| 15 | 7 | 100 | 0 | 0 | 0 | 30.0 | 0.484 | 32 | 1 |
| 18 | 1 | 103 | 30 | 38 | 83 | 43.3 | 0.183 | 33 | 0 |
| 43 | 9 | 171 | 110 | 24 | 240 | 45.4 | 0.721 | 54 | 1 |
| 49 | 7 | 105 | 0 | 0 | 0 | 0.0 | 0.305 | 24 | 0 |
| 60 | 2 | 84 | 0 | 0 | 0 | 0.0 | 0.304 | 21 | 0 |
| 78 | 0 | 131 | 0 | 0 | 0 | 43.2 | 0.270 | 26 | 1 |
| 81 | 2 | 74 | 0 | 0 | 0 | 0.0 | 0.102 | 22 | 0 |
| 84 | 5 | 137 | 108 | 0 | 0 | 48.8 | 0.227 | 37 | 1 |
| 106 | 1 | 96 | 122 | 0 | 0 | 22.4 | 0.207 | 27 | 0 |
| 125 | 1 | 88 | 30 | 42 | 99 | 55.0 | 0.496 | 26 | 1 |
| 172 | 2 | 87 | 0 | 23 | 0 | 28.9 | 0.773 | 25 | 0 |
| 177 | 0 | 129 | 110 | 46 | 130 | 67.1 | 0.319 | 26 | 1 |
| 193 | 11 | 135 | 0 | 0 | 0 | 52.3 | 0.578 | 40 | 1 |
| 222 | 7 | 119 | 0 | 0 | 0 | 25.2 | 0.209 | 37 | 0 |
| 261 | 3 | 141 | 0 | 0 | 0 | 30.0 | 0.761 | 27 | 1 |
| 266 | 0 | 138 | 0 | 0 | 0 | 36.3 | 0.933 | 25 | 1 |
| 269 | 2 | 146 | 0 | 0 | 0 | 27.5 | 0.240 | 28 | 1 |
| 300 | 0 | 167 | 0 | 0 | 0 | 32.3 | 0.839 | 30 | 1 |
| 332 | 1 | 180 | 0 | 0 | 0 | 43.3 | 0.282 | 41 | 1 |
| 336 | 0 | 117 | 0 | 0 | 0 | 33.8 | 0.932 | 44 | 0 |
| 347 | 3 | 116 | 0 | 0 | 0 | 23.5 | 0.187 | 23 | 0 |
| 357 | 13 | 129 | 0 | 30 | 0 | 39.9 | 0.569 | 44 | 1 |
| 362 | 5 | 103 | 108 | 37 | 0 | 39.2 | 0.305 | 65 | 0 |
| 426 | 0 | 94 | 0 | 0 | 0 | 0.0 | 0.256 | 25 | 0 |
| 430 | 2 | 99 | 0 | 0 | 0 | 22.2 | 0.108 | 23 | 0 |
| 435 | 0 | 141 | 0 | 0 | 0 | 42.4 | 0.205 | 29 | 1 |
| 453 | 2 | 119 | 0 | 0 | 0 | 19.6 | 0.832 | 72 | 0 |
| 468 | 8 | 120 | 0 | 0 | 0 | 30.0 | 0.183 | 38 | 1 |
| 484 | 0 | 145 | 0 | 0 | 0 | 44.2 | 0.630 | 31 | 1 |
| 494 | 3 | 80 | 0 | 0 | 0 | 0.0 | 0.174 | 22 | 0 |
| 522 | 6 | 114 | 0 | 0 | 0 | 0.0 | 0.189 | 26 | 0 |
| 533 | 6 | 91 | 0 | 0 | 0 | 29.8 | 0.501 | 31 | 0 |
| 535 | 4 | 132 | 0 | 0 | 0 | 32.9 | 0.302 | 23 | 1 |
| 549 | 4 | 189 | 110 | 31 | 0 | 28.5 | 0.680 | 37 | 0 |
| 589 | 0 | 73 | 0 | 0 | 0 | 21.1 | 0.342 | 25 | 0 |
| 597 | 1 | 89 | 24 | 19 | 25 | 27.8 | 0.559 | 21 | 0 |
| 601 | 6 | 96 | 0 | 0 | 0 | 23.7 | 0.190 | 28 | 0 |
| 604 | 4 | 183 | 0 | 0 | 0 | 28.4 | 0.212 | 36 | 1 |
| 619 | 0 | 119 | 0 | 0 | 0 | 32.4 | 0.141 | 24 | 1 |
| 643 | 4 | 90 | 0 | 0 | 0 | 28.0 | 0.610 | 31 | 0 |
| 691 | 13 | 158 | 114 | 0 | 0 | 42.3 | 0.257 | 44 | 1 |
| 697 | 0 | 99 | 0 | 0 | 0 | 25.0 | 0.253 | 22 | 0 |
| 703 | 2 | 129 | 0 | 0 | 0 | 38.5 | 0.304 | 41 | 0 |
| 706 | 10 | 115 | 0 | 0 | 0 | 0.0 | 0.261 | 30 | 1 |
#Veamos el boxplot para visualizar los outliers
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['BloodPressure'], color='lightseagreen')
plt.title('Boxplot de BloodPressure')
plt.xlabel('BloodPressure')
display(df['BloodPressure'].describe())
count 768.000000
mean 69.105469
std 19.355807
min 0.000000
25% 62.000000
50% 72.000000
75% 80.000000
max 122.000000
Name: BloodPressure, dtype: float64
# Hagamos manejo de los valores "0" en `BloodPressure`
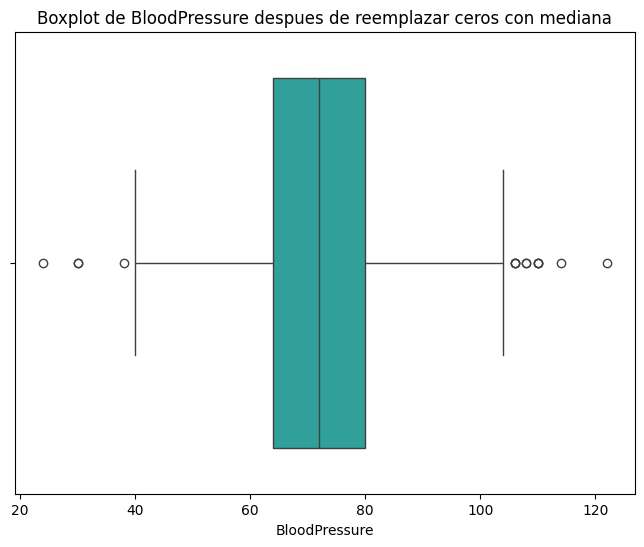
#OPCION 1: Reemplazar los ceros con la mediana de la columna
df['BloodPressure']= df['BloodPressure'].replace(0, df['BloodPressure'].median())
#Visualizar el cambio
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['BloodPressure'], color='lightseagreen')
plt.title('Boxplot de BloodPressure despues de reemplazar ceros con mediana')
plt.xlabel('BloodPressure')
display(df['BloodPressure'].describe())
count 768.000000
mean 72.386719
std 12.096642
min 24.000000
25% 64.000000
50% 72.000000
75% 80.000000
max 122.000000
Name: BloodPressure, dtype: float64
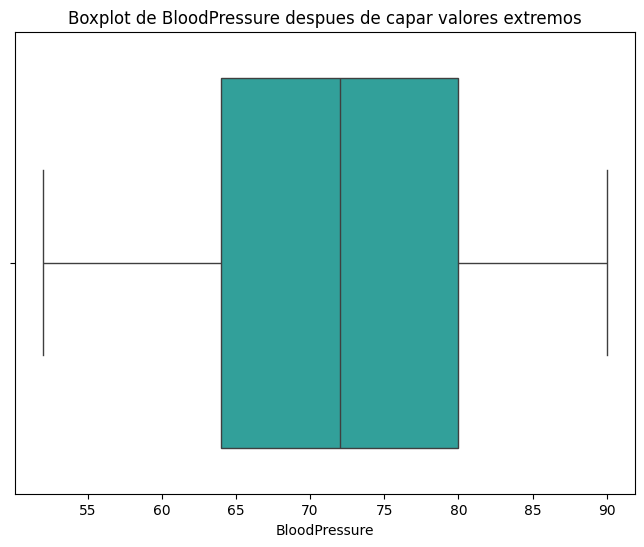
# OPCION 2: Capar o limitar los valores extremos en `BloodPressure`
lower_cap = df['BloodPressure'].quantile(0.05)
upper_cap = df['BloodPressure'].quantile(0.95)
df['BloodPressure'] = df['BloodPressure'].clip(lower_cap, upper_cap)
# Visualizar el cambio
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['BloodPressure'], color='lightseagreen')
plt.title('Boxplot de BloodPressure despues de capar valores extremos')
plt.xlabel('BloodPressure')
display(df['BloodPressure'].describe())
count 768.000000
mean 72.158854
std 10.443155
min 52.000000
25% 64.000000
50% 72.000000
75% 80.000000
max 90.000000
Name: BloodPressure, dtype: float64
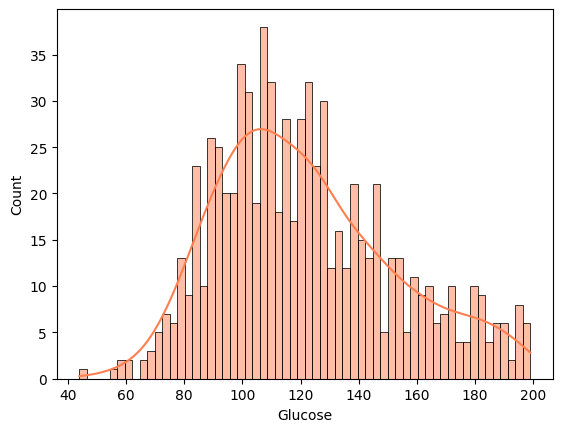
#Outliers por el metodo Z-score para la variable 'Glucose'
mean= df['Glucose'].mean()
std= df['Glucose'].std()
z_scores = (df['Glucose'] - mean) / std
outliers_z = df[(z_scores > 3) | (z_scores < -3)]
print("Outliers en 'Glucose' usando Z-score:")
display(outliers_z)
Outliers en 'Glucose' usando Z-score:
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 75 | 1 | 0 | 52 | 20 | 0 | 24.7 | 0.140 | 22 | 0 |
| 182 | 1 | 0 | 74 | 20 | 23 | 27.7 | 0.299 | 21 | 0 |
| 342 | 1 | 0 | 68 | 35 | 0 | 32.0 | 0.389 | 22 | 0 |
| 349 | 5 | 0 | 80 | 32 | 0 | 41.0 | 0.346 | 37 | 1 |
| 502 | 6 | 0 | 68 | 41 | 0 | 39.0 | 0.727 | 41 | 1 |
# La glucosa es una variable critica para el diagnostico de diabetes, por lo que eliminaremos los outliers detectados dado que es imputarlos podria distorsionar el analisis.
df.drop(outliers_z.index, axis=0, inplace=True)
sns.histplot(df['Glucose'], bins=60, kde=True, color='coral')
<Axes: xlabel='Glucose', ylabel='Count'>
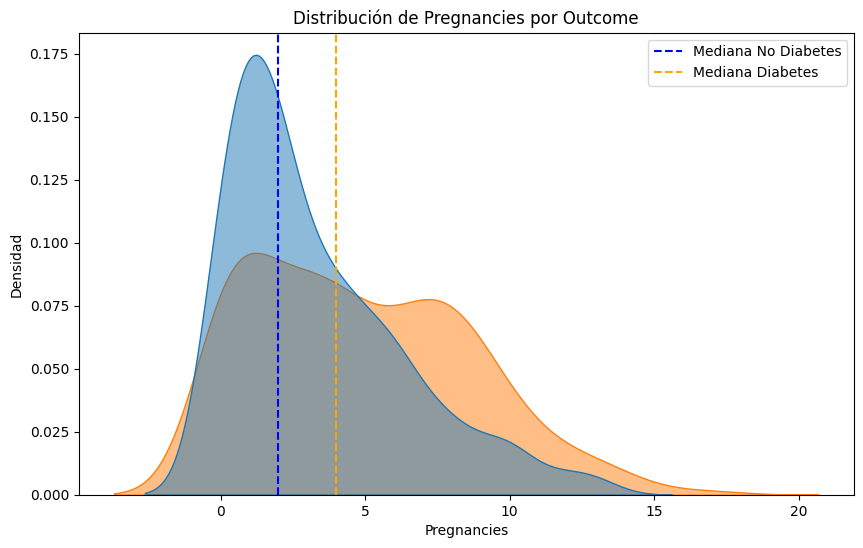
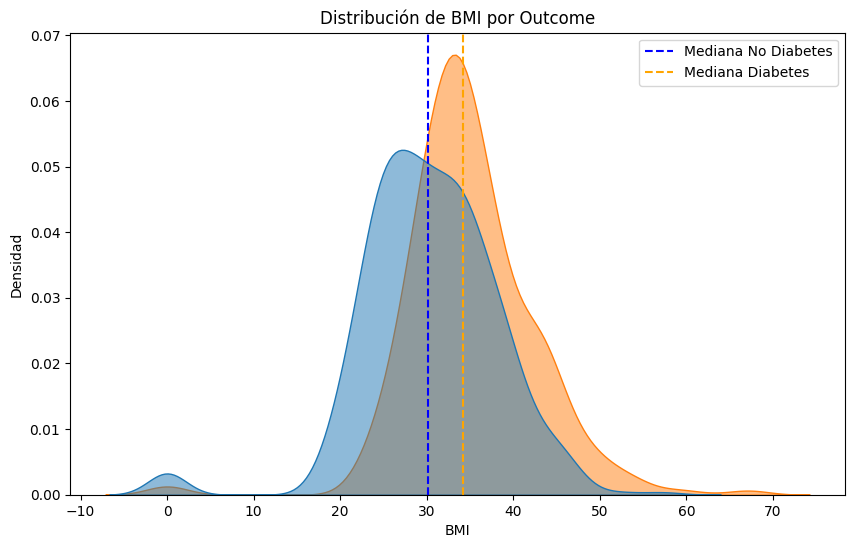
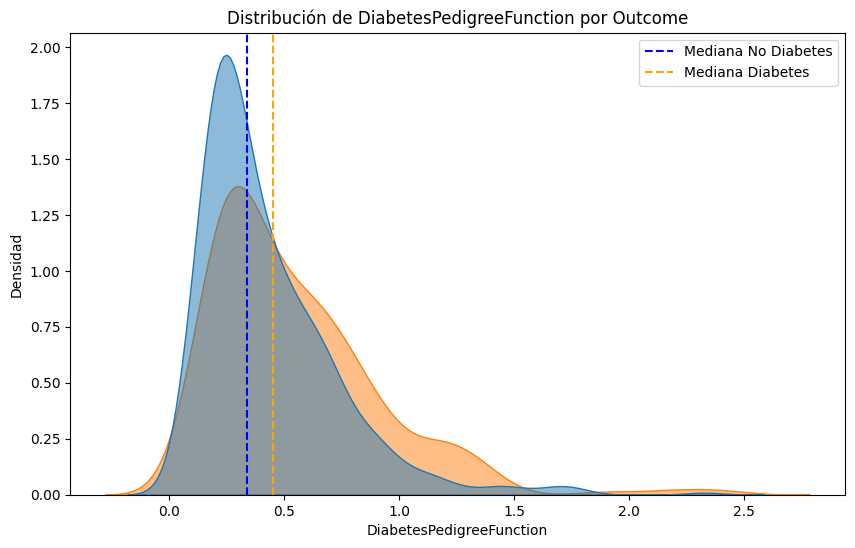
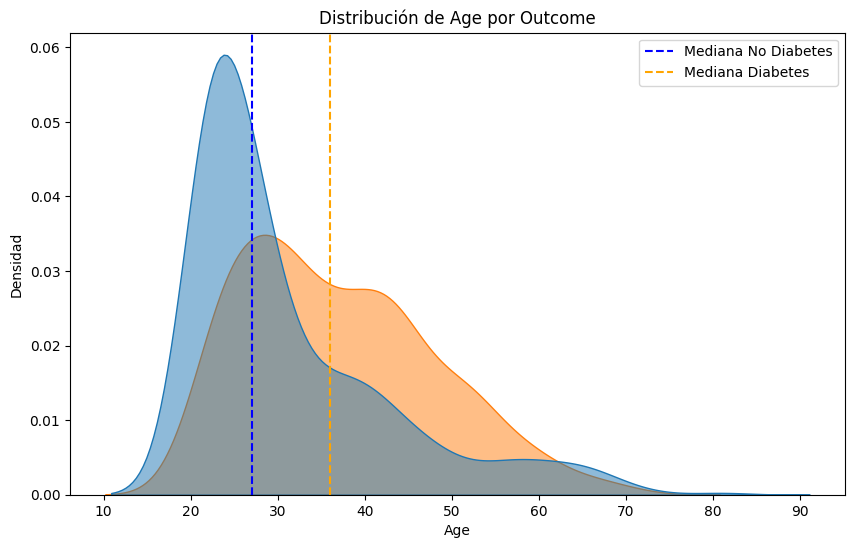
#Comparemos las distribuciones de cada parametro para los pacientes con y sin diabetes, resaltando la mediana de cada grupo.
for column in df.select_dtypes(include=['float64', 'int64']).columns:
plt.figure(figsize=(10, 6))
sns.kdeplot(data=df, x=column, hue='Outcome', fill=True, common_norm=False, alpha=0.5)
# Calcular y marcar las medianas
median_no_diabetes = df[df['Outcome'] == 0][column].median()
median_diabetes = df[df['Outcome'] == 1][column].median()
plt.axvline(median_no_diabetes, color='blue', linestyle='--', label='Mediana No Diabetes')
plt.axvline(median_diabetes, color='orange', linestyle='--', label='Mediana Diabetes')
plt.title(f'Distribución de {column} por Outcome')
plt.xlabel(column)
plt.ylabel('Densidad')
plt.legend()
plt.show()
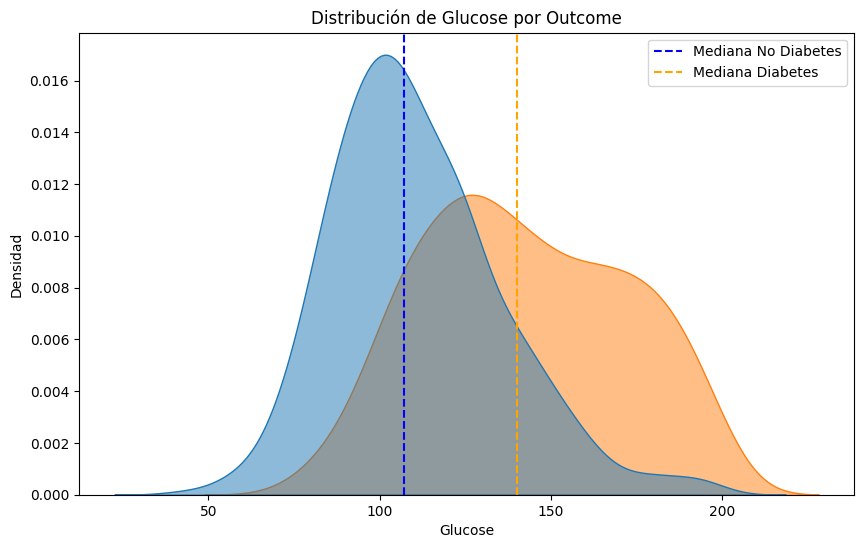
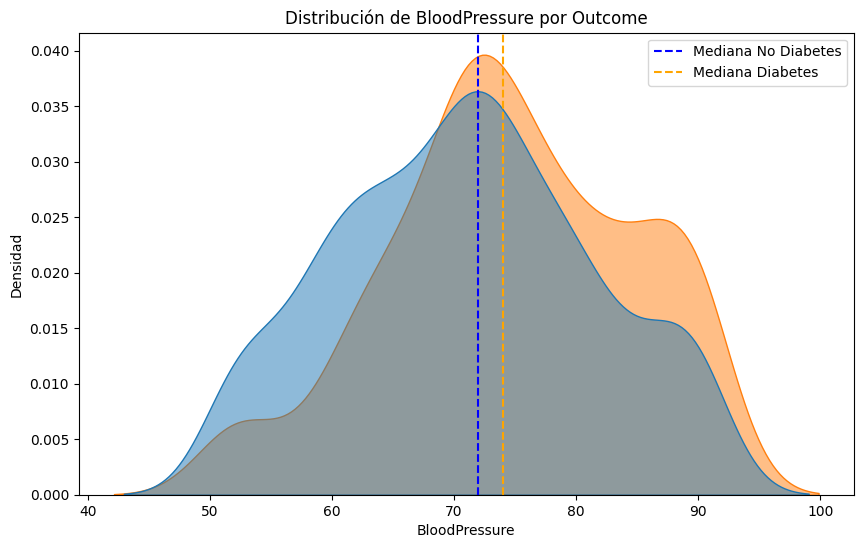
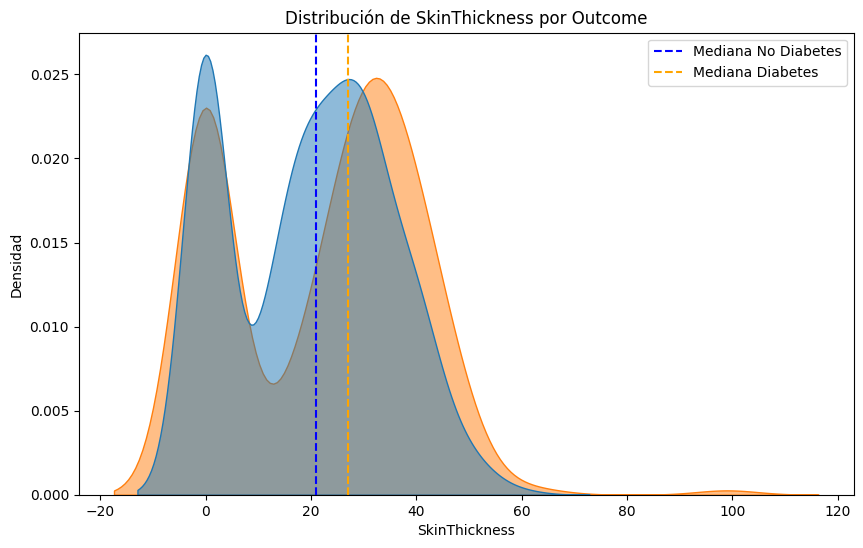
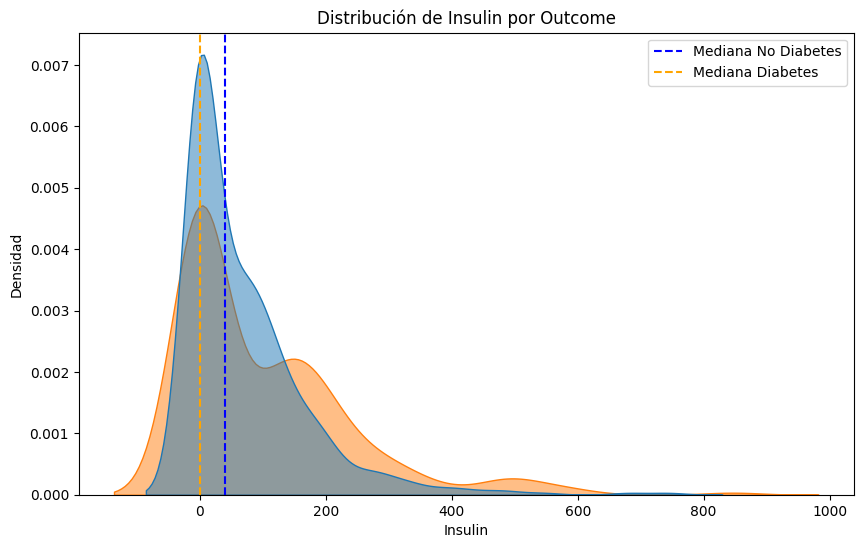
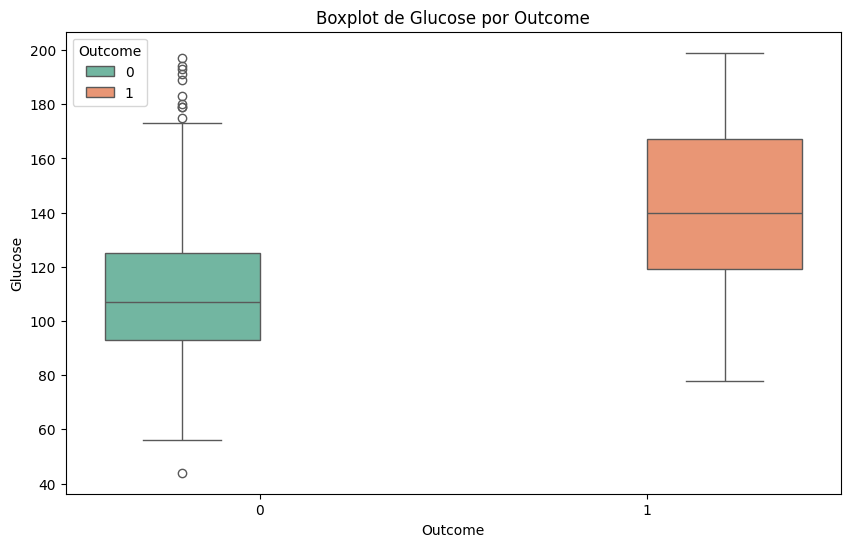
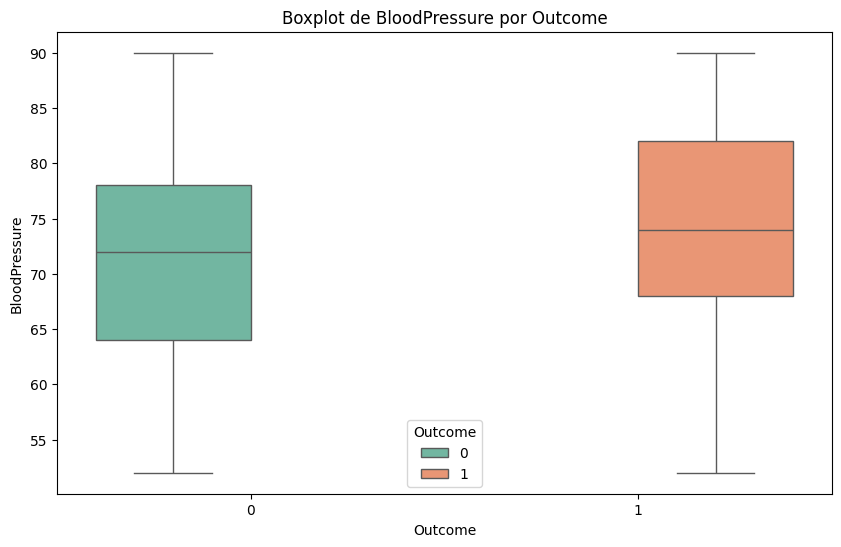
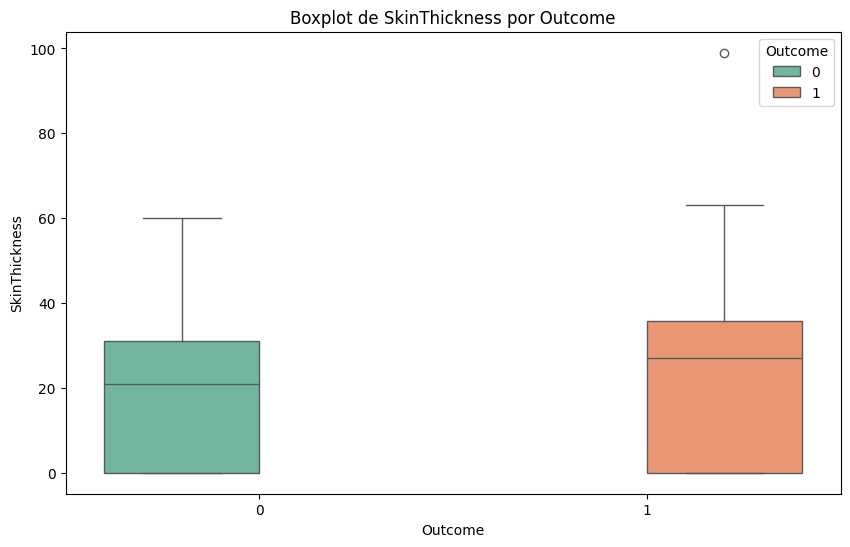
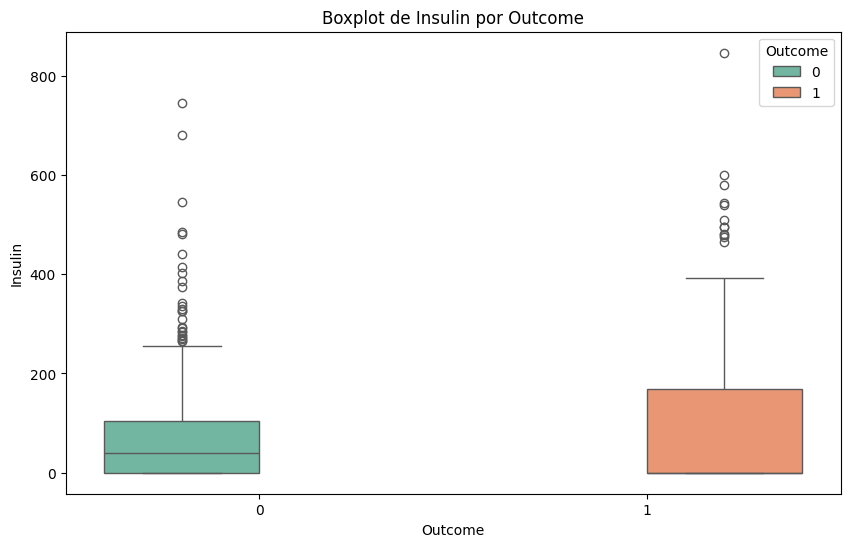
#Lo mismo pero con boxplots
for column in df.select_dtypes(include=['float64', 'int64']).columns:
plt.figure(figsize=(10, 6))
sns.boxplot(x='Outcome', y=column, data=df, hue='Outcome', palette='Set2')
plt.title(f'Boxplot de {column} por Outcome')
plt.xlabel('Outcome')
plt.ylabel(column)
plt.show()
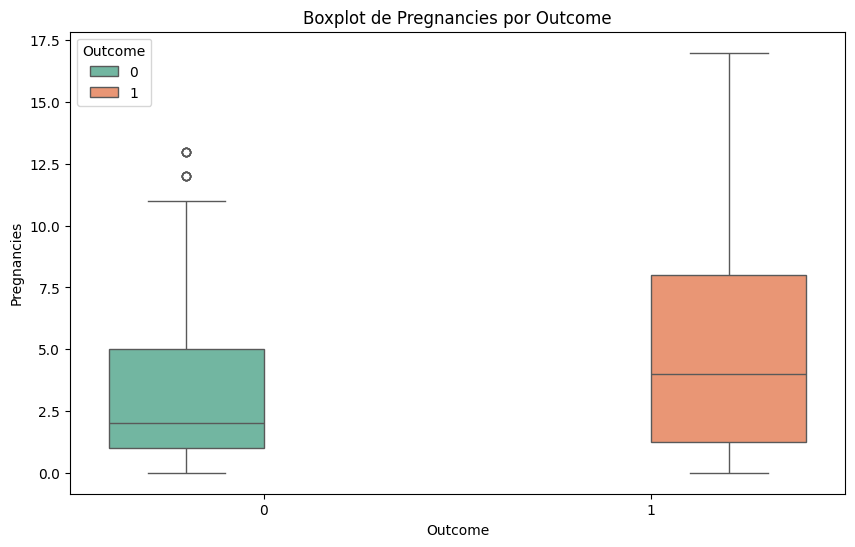
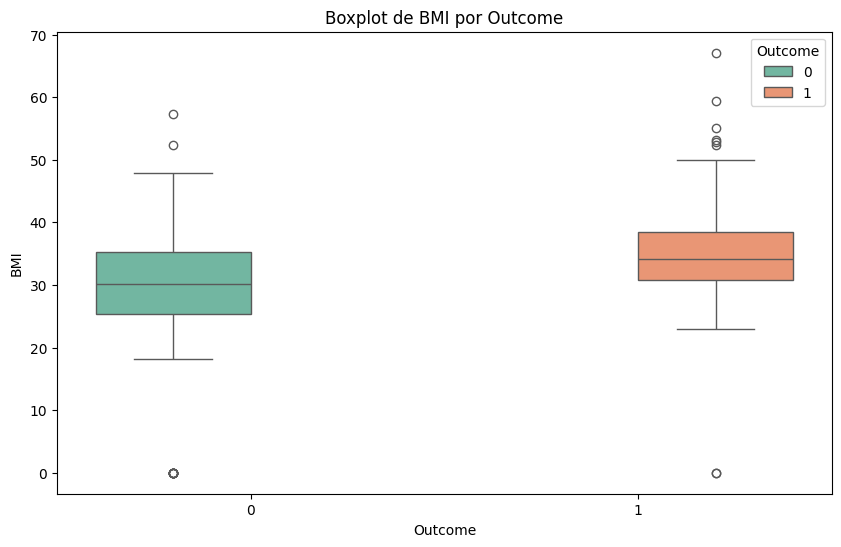
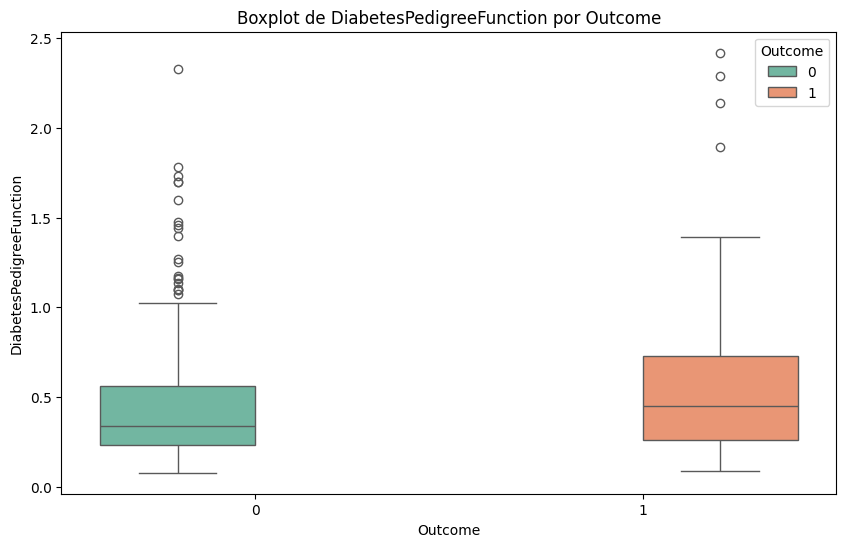
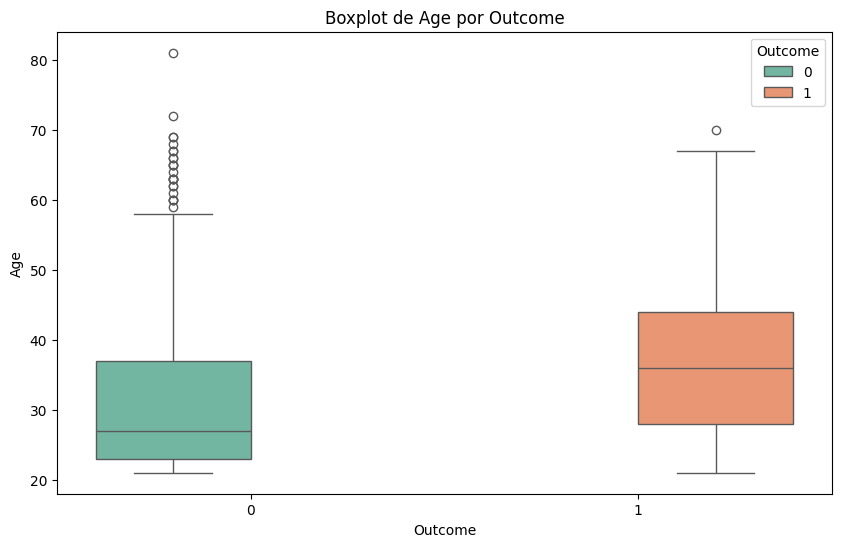
🧭 ¿Qué hacer con outliers una vez identificados?#
Paso 1: Verificar si es error#
Preguntas rápidas:
¿Está fuera del rango lógico? (rating 9 cuando es 1–5)
¿Unidad incorrecta? (shipping_cost 3000 cuando normalmente es 5–30)
¿Duplicados o registros repetidos?
¿Formato/parseo malo? (fecha “2099-99-99”)
✅ Si es error confirmado:
Corregir si hay fuente confiable.
Si no se puede corregir: convertir a
NaNy tratar como missing (imputar/flag).
Paso 2: Si no es error, decidir estrategia según objetivo#
A) Mantenerlos (si son parte real del negocio)#
Los extremos importan (fraude, VIP, casos críticos).
B) Capar/Winsorizar (limitar extremos)#
Cambias valores extremos por un límite superior/inferior (ej. P1 y P99).
Los extremos dominan gráficos/estadísticas.
👉 Recomendación:
Registrar la operación (no hacerlo “en silencio”).
Guardar el original si lo necesitas después.
C) Eliminar (último recurso)#
Son errores y no se pueden corregir.
O están contaminando el análisis y no representan el fenómeno.
⚠️ Riesgo:
Sesgo: puedes eliminar justo los casos que importan.
¿Qué aprendimos hoy? 🧠#
Una distribución describe cómo se reparten los valores; la forma (sesgo, colas, picos) cambia la interpretación
La normal es una distribución simétrica tipo campana; normalidad es aproximarse a esa forma para habilitar reglas útiles
En normalidad, la regla 68–95–99
Un histograma se lee por forma, colas y picos; los bins pueden engañar → complementa con boxplot/percentiles
Variabilidad: rango y std son sensibles a extremos
IQR es robusto y describe el centro del 50%
Outliers:
IQR es mejor en sesgo/colas largas
Z-score funciona mejor si hay normalidad aproximada
Próxima Clase ⏭️:#
Funciones de file
Segmentación de clientes
GitHub
Sesión Práctica 💪: Habilidades técnicas python y GitHub#
Ejercicios: funciones de fila para segmentación de clientes (condicionales + bucles) + mini apartado GitHub#
🎯 Objetivos de la sesión#
Al final de esta clase podrás:
Crear funciones de fila usando
if/elif/elsey manipulando correctamente nulos y outliers.Integrar bucles dentro de funciones para evaluar reglas, contar condiciones o aplicar “scoring”.
Aplicar segmentaciones típicas.
Entender el flujo básico de GitHub para entregar y versionar notebooks.
🧭 Agenda#
Repaso rápido (10 min): row functions, condicionales y loops.
Ejercicio 1 (20 min): segmentación por reglas (VIP/Loyal/At risk).
Ejercicio 2 (25 min): scoring por puntos con bucle (customer score).
Ejercicio 3 (20 min): flags de calidad + segmentación “limpia”.
Mini apartado GitHub (15–20 min): repo, commit, push, README.
Ejercicio 1:#
Diseña una función que recorra las columnas numericas de un dataset, cuente e indentifique los
outliersde cada columna.Crea funciones que permitan darle diferentes manejos a los outliers: eliminar, reemplazar o capar.
Identifica las “reglas” o “rangos” para clasificar a un paciente como riesgo alto, bajo, medio de desarrollar diabetes y agrega recomendaciones para ellos.
Diseña una función de fila que genere una columna en el dataset con la respectiva clasificación.
Utiliza el dataset de Diabetes, aunque las funciones de limpieza deberían funcionar tambien para otros datasets.
diabetes_url=’https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/diabetes.csv’
df = pd.read_csv('https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/diabetes.csv')
display(df.sample(10))
df.info()
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 158 | 2 | 88 | 74 | 19 | 53 | 29.0 | 0.229 | 22 | 0 |
| 712 | 10 | 129 | 62 | 36 | 0 | 41.2 | 0.441 | 38 | 1 |
| 19 | 1 | 115 | 70 | 30 | 96 | 34.6 | 0.529 | 32 | 1 |
| 168 | 4 | 110 | 66 | 0 | 0 | 31.9 | 0.471 | 29 | 0 |
| 326 | 1 | 122 | 64 | 32 | 156 | 35.1 | 0.692 | 30 | 1 |
| 284 | 2 | 108 | 80 | 0 | 0 | 27.0 | 0.259 | 52 | 1 |
| 82 | 7 | 83 | 78 | 26 | 71 | 29.3 | 0.767 | 36 | 0 |
| 642 | 6 | 147 | 80 | 0 | 0 | 29.5 | 0.178 | 50 | 1 |
| 422 | 0 | 102 | 64 | 46 | 78 | 40.6 | 0.496 | 21 | 0 |
| 597 | 1 | 89 | 24 | 19 | 25 | 27.8 | 0.559 | 21 | 0 |
<class 'pandas.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
Ejercicio 2:#
Diseña una función que recorra las columnas numericas de un dataset, cuente e indentifique los
outliersde cada columna.Crea funciones que permitan darle diferentes manejos a los outliers: eliminar, reemplazar o capar.
Identifica las “reglas” o “rangos” para realizar una segmentación tipo RFM.
Recency: días desde última compra (si tienes fechas)
Frequency: # pedidos por customer (order_id)
Monetary: suma de total_amount
Categorías típicas:
VIP, Loyal, At risk, New, Low value
Diseña una función de fila que genere una columna en el dataset con la respectiva clasificación.
sales_url=’https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/Online_Sales.csv’
df = pd.read_csv('https://raw.githubusercontent.com/gbuvoli/Datasets/refs/heads/main/Online_Sales.csv')
display(df.sample(10))
df.info()
| CustomerID | Transaction_ID | Transaction_Date | Product_SKU | Product_Description | Product_Category | Quantity | Avg_Price | Delivery_Charges | Coupon_Status | |
|---|---|---|---|---|---|---|---|---|---|---|
| 403 | 16218 | 16971 | 1/3/2019 | GGOENEBJ079499 | Nest Learning Thermostat 3rd Gen-USA - Stainle... | Nest-USA | 2 | 153.71 | 6.50 | Not Used |
| 30733 | 12484 | 34677 | 8/4/2019 | GGOEYOCR077799 | YouTube Hard Cover Journal | Notebooks & Journals | 5 | 11.99 | 34.94 | Not Used |
| 38321 | 18109 | 38313 | 9/16/2019 | GGOEGFKQ020399 | Google Laptop and Cell Phone Stickers | Office | 1 | 2.99 | 6.00 | Used |
| 27399 | 14732 | 33097 | 7/18/2019 | GGOEGAAJ080613 | Google Men's Bike Short Sleeve Tee Charcoal | Apparel | 1 | 19.99 | 6.00 | Clicked |
| 22895 | 17744 | 30687 | 6/18/2019 | GGOEGAAL059013 | Google Men's Short Sleeve Performance Badge Te... | Apparel | 1 | 15.39 | 6.00 | Used |
| 6427 | 15880 | 20941 | 2/21/2019 | GGOEGGOA017399 | Maze Pen | Office | 200 | 0.99 | 6.50 | Used |
| 33669 | 15518 | 36082 | 8/19/2019 | GGOEGCMB020932 | Suitcase Organizer Cubes | Bags | 1 | 12.31 | 12.99 | Clicked |
| 16033 | 13798 | 26946 | 5/1/2019 | GGOEWAEA083899 | Waze Dress Socks | Waze | 1 | 8.99 | 6.00 | Not Used |
| 26401 | 16477 | 32596 | 7/13/2019 | GGOEGAAQ033917 | Google Men's Vintage Badge Tee White | Apparel | 1 | 5.70 | 6.00 | Used |
| 6240 | 16327 | 20818 | 2/19/2019 | GGOEYFKQ020699 | YouTube Custom Decals | Office | 1 | 1.99 | 20.00 | Not Used |
<class 'pandas.DataFrame'>
RangeIndex: 52924 entries, 0 to 52923
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CustomerID 52924 non-null int64
1 Transaction_ID 52924 non-null int64
2 Transaction_Date 52924 non-null str
3 Product_SKU 52924 non-null str
4 Product_Description 52924 non-null str
5 Product_Category 52924 non-null str
6 Quantity 52924 non-null int64
7 Avg_Price 52924 non-null float64
8 Delivery_Charges 52924 non-null float64
9 Coupon_Status 52924 non-null str
dtypes: float64(2), int64(3), str(5)
memory usage: 4.0 MB