
Sprint 3 : Semana 1 - Introducción a Bases de datos relacionales y Querys Basicas#
📊 Explorar KPIs Financieros con SQL
Cómo usar SQL para analizar métricas financieras desde bases de datos relacionales.
Imagen de referencia: entorno SQL
Duración total: 1h 20 min
- Parte 1: Fundamentos de BD relacionales (tablas, PK/FK, ERD).
- Parte 2: Consultas básicas —
SELECT,FROM,WHERE,ORDER BY. - Parte 3: Agregaciones
SUM,AVG,COUNT— agrupacionesGROUP BY, condicionesCASE WHEN,BETWEEN,OR,AND,IN, cortes por fecha. - Parte 4: Detección de problemas de calidad de datos (valores nulos, duplicados) con
IS NOT NULL,DISTINCT. - Parte 5: Buenas prácticas + precisión con tipos de datos:
CAST,ROUND, comentarios.
🎯 Objetivos de aprendizaje
- Entender la estructura de una base de datos relacional y su esquema.
- Identificar llaves primarias (PK) y foráneas (FK) y su rol en el modelo.
- Ejecutar consultas básicas para explorar, filtrar, ordenar y agrupar datos.
- Aplicar funciones de fecha y numéricas para calcular KPIs financieros.
- Detectar problemas de calidad de datos (nulos, duplicados) durante la exploración.
🧠 Introducción a SQL (Structured Query Language)
Material de apoyo para la clase – lectura rápida y visual para entender qué es SQL y por qué importa.
📚 ¿Qué es una base de datos relacional?
Una base de datos relacional es un sistema estructurado donde los datos se almacenan en tablas conectadas entre sí mediante claves, lo que permite consultar, combinar y mantener la información de forma coherente usando SQL.
💻 ¿Qué es SQL?
SQL es el lenguaje estándar para consultar, modificar y analizar datos en bases de datos relacionales como PostgreSQL, MySQL o SQL Server.
Es un lenguaje declarativo: describes qué información necesitas y el motor decide cómo obtenerla.
books
SELECT title, num_pages
FROM books
WHERE num_pages > 300;⚙️ ¿Cómo funciona una consulta SQL?
- El cliente (Jupyter, IDE, BI, etc.) envía la consulta al servidor.
- El motor SQL la analiza, valida la sintaxis y los permisos.
- El optimizador elige el plan de ejecución (uso de índices, joins, etc.).
- Se ejecuta el plan y se retorna un conjunto de filas y columnas como resultado.
🌎 ¿En qué ámbitos se usa SQL?
- Data Analyst: extraer, limpiar y resumir datos para KPIs y dashboards.
- Data Scientist: preparar datasets para modelos y experimentos.
- Data Engineer: construir pipelines sobre RDBMS (sistemas de bases relacionales).
- BI / Producto / Finanzas: consultas directas para métricas de negocio.
💰 Ejemplos típicos en negocio y finanzas
- Ingresos, costos y márgenes.
- Ticket promedio por cliente o transacción.
- Tendencias temporales por día, semana o mes.
- Análisis de cohortes y comportamiento de usuarios en el tiempo.
🧩 Comandos fundamentales de SQL
Los bloques que usarás todo el tiempo:
SELECT → leer datos
WHERE → filtros
ORDER BY → ordenar
GROUP BY / HAVING → agregaciones
JOIN → unir tablas
COUNT, AVG, SUM, ROUND → funciones
subconsultas (subqueries)
🎯 Importancia de SQL para un Data Analyst
- Permite acceso directo a los datos desde la fuente.
- Respuestas rápidas sin necesidad de procesos ETL complejos.
- Posibilidad de definir KPIs reproducibles y auditables.
- Base sólida para integrarte con Python, R, BI y otros entornos.
Flujo típico de trabajo: SQL → (opcional) Pandas → Visualización (BI / Notebook)
💡 Tips iniciales para escribir buen SQL
- Empieza simple y valida tus filtros antes de unir o agrupar.
- Comenta tu código SQL y usa alias claros con
AS. - Evita
SELECT *en producción; especifica siempre las columnas. - Usa
LIMITcuando estés explorando datos. - Formatea e indenta tus consultas para facilitar lectura y mantenimiento.
Entendiendo el esquema relacional#
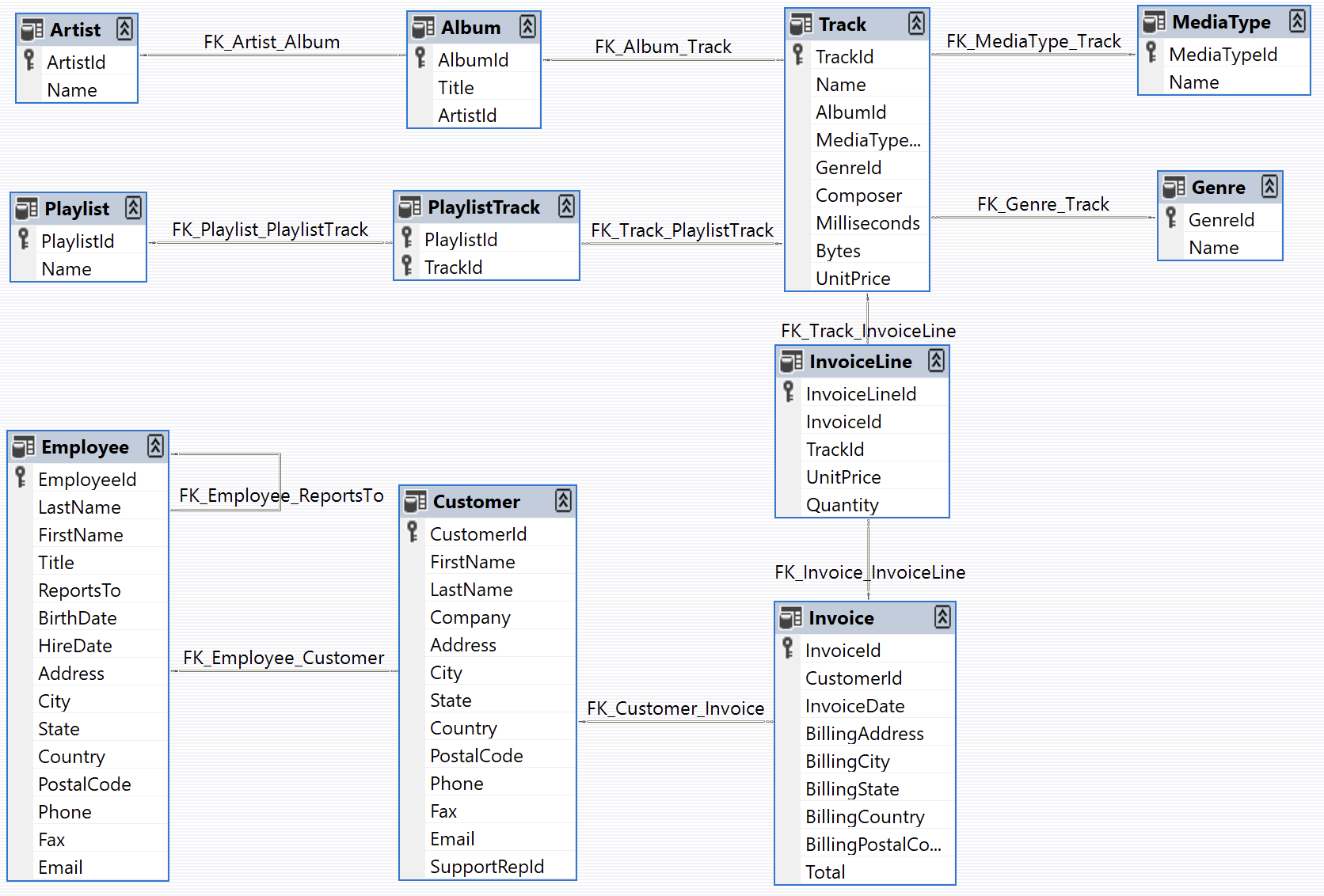
🧩 Ejercicio 1#
¿Qué preguntas de negocio podrías responder con este esquema? (p. ej., promedio de facturacion por genero musical, cantidad de albumes por artista, evolución anual de las ventas por album).
Llaves primarias, foráneas y relaciones#
PK (Primary Key): asegura unicidad por fila (ej.
Artist.Artist_id).FK (Foreign Key): referencia a otra tabla (ej.
Album.Artist_id→Artist.Artist_id).
Estas llaves articulan el modelo relacional y permiten combinar información de diferentes tablas.
🧩 Ejercicio 2#
Marca (en papel o mentalmente) las relaciones entre Tracks, Albums, Artists, Invoices e InvoiceLines.
Piensa cómo combinarías tablas para responder a: “¿Qué artista vende pistas con mayor ingreso promedio (promedio de UnitPrice * Quantity por track)?”
# Paso 1: Descargar el archivo desde GitHub
!curl -L -o chinook.db https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite
# Paso 2: Instalar ipython-sql si no está instalada
!pip install -q ipython-sql
# Paso 3: Cargar extensión y conectar a la base
%load_ext sql
%config SqlMagic.style = 'PLAIN_COLUMNS'
%sql sqlite:///chinook.db
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 984k 100 984k 0 0 1506k 0 --:--:-- --:--:-- --:--:-- 1506k
import sqlite3
import pandas as pd
# Hacemos la conexión a la Database
conn = sqlite3.connect("chinook.db")
# Redactamos la Query
query= '''
SELECT name
FROM sqlite_master
WHERE type='table';
'''
#Consultamos e imprimimos resultado
pd.read_sql(query, conn)
| name | |
|---|---|
| 0 | Album |
| 1 | Artist |
| 2 | Customer |
| 3 | Employee |
| 4 | Genre |
| 5 | Invoice |
| 6 | InvoiceLine |
| 7 | MediaType |
| 8 | Playlist |
| 9 | PlaylistTrack |
| 10 | Track |
Conectar a la base de datos y explorar tablas con SQL (Simular)#
1: Descarga la database Chinook
Visita: Sqlite online to open the database and run queries. SqliteOnline
Carga la base de datos y ejecuta la siguiente consulta para inspeccionar la tabla
tracks:
SELECT *
FROM track
LIMIT 10;
Observa: tipos de datos, rangos, valores faltantes o atípicos.
¿Qué columnas pueden servir como KPIs?
UnitPrice → valor base de cada pista (precio de catálogo).
Milliseconds → duración; sirve como feature de contenido.
Bytes → tamaño del archivo; otra dimensión técnica.
Buenas prácticas para SQL limpio#
Palabras clave en MAYÚSCULAS (
SELECT,WHERE,GROUP BY).Indentación consistente (una operación por línea).
Alias claros (
AS) y comentarios para lógica compleja.Usa
LIMITen exploración para controlar tiempos.Evita
SELECT *en producción; especifica columnas.Nombres de columnas y tablas coherentes y expresivos.
SELECT - FROM - WHERE#
# Podemos indicar una o varios campos que queremos consultar
query='''
SELECT ArtistId, Title
FROM Album;
'''
pd.read_sql(query, conn)
| ArtistId | Title | |
|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You |
| 1 | 2 | Balls to the Wall |
| 2 | 2 | Restless and Wild |
| 3 | 1 | Let There Be Rock |
| 4 | 3 | Big Ones |
| ... | ... | ... |
| 342 | 226 | Respighi:Pines of Rome |
| 343 | 272 | Schubert: The Late String Quartets & String Qu... |
| 344 | 273 | Monteverdi: L'Orfeo |
| 345 | 274 | Mozart: Chamber Music |
| 346 | 275 | Koyaanisqatsi (Soundtrack from the Motion Pict... |
347 rows × 2 columns
query='''
SELECT FirstName,LastName,City FROM Employee;
'''
pd.read_sql(query, conn)
| FirstName | LastName | City | |
|---|---|---|---|
| 0 | Andrew | Adams | Edmonton |
| 1 | Nancy | Edwards | Calgary |
| 2 | Jane | Peacock | Calgary |
| 3 | Margaret | Park | Calgary |
| 4 | Steve | Johnson | Calgary |
| 5 | Michael | Mitchell | Calgary |
| 6 | Robert | King | Lethbridge |
| 7 | Laura | Callahan | Lethbridge |
Mostrar los nombres y países de los clientes de Brasil
query='''
SELECT FirstName, LastName, city
FROM Customer
WHERE Country = 'Brazil';
'''
pd.read_sql(query, conn)
| FirstName | LastName | City | |
|---|---|---|---|
| 0 | Luís | Gonçalves | São José dos Campos |
| 1 | Eduardo | Martins | São Paulo |
| 2 | Alexandre | Rocha | São Paulo |
| 3 | Roberto | Almeida | Rio de Janeiro |
| 4 | Fernanda | Ramos | Brasília |
Clientes de Canadá o Alemania
query='''
SELECT FirstName, LastName, City, Country
FROM Customer
WHERE Country = 'Canada' OR Country = 'Germany';
'''
pd.read_sql(query, conn)
| FirstName | LastName | City | Country | |
|---|---|---|---|---|
| 0 | Leonie | Köhler | Stuttgart | Germany |
| 1 | François | Tremblay | Montréal | Canada |
| 2 | Mark | Philips | Edmonton | Canada |
| 3 | Jennifer | Peterson | Vancouver | Canada |
| 4 | Robert | Brown | Toronto | Canada |
| 5 | Edward | Francis | Ottawa | Canada |
| 6 | Martha | Silk | Halifax | Canada |
| 7 | Aaron | Mitchell | Winnipeg | Canada |
| 8 | Ellie | Sullivan | Yellowknife | Canada |
| 9 | Hannah | Schneider | Berlin | Germany |
| 10 | Fynn | Zimmermann | Frankfurt | Germany |
| 11 | Niklas | Schröder | Berlin | Germany |
Clientes del estado de California
query='''
SELECT CustomerId,FirstName,City
FROM Customer
WHERE State='CA';
'''
pd.read_sql(query, conn)
| CustomerId | FirstName | City | |
|---|---|---|---|
| 0 | 16 | Frank | Mountain View |
| 1 | 19 | Tim | Cupertino |
| 2 | 20 | Dan | Mountain View |
Clientes que no vivan en USA
query='''
SELECT FirstName, LastName, City, Country
FROM Customer
WHERE Country != "USA";
'''
pd.read_sql(query, conn)
| FirstName | LastName | City | Country | |
|---|---|---|---|---|
| 0 | Luís | Gonçalves | São José dos Campos | Brazil |
| 1 | Leonie | Köhler | Stuttgart | Germany |
| 2 | François | Tremblay | Montréal | Canada |
| 3 | Bjørn | Hansen | Oslo | Norway |
| 4 | František | Wichterlová | Prague | Czech Republic |
| 5 | Helena | Holý | Prague | Czech Republic |
| 6 | Astrid | Gruber | Vienne | Austria |
| 7 | Daan | Peeters | Brussels | Belgium |
| 8 | Kara | Nielsen | Copenhagen | Denmark |
| 9 | Eduardo | Martins | São Paulo | Brazil |
| 10 | Alexandre | Rocha | São Paulo | Brazil |
| 11 | Roberto | Almeida | Rio de Janeiro | Brazil |
| 12 | Fernanda | Ramos | Brasília | Brazil |
| 13 | Mark | Philips | Edmonton | Canada |
| 14 | Jennifer | Peterson | Vancouver | Canada |
| 15 | Robert | Brown | Toronto | Canada |
| 16 | Edward | Francis | Ottawa | Canada |
| 17 | Martha | Silk | Halifax | Canada |
| 18 | Aaron | Mitchell | Winnipeg | Canada |
| 19 | Ellie | Sullivan | Yellowknife | Canada |
| 20 | João | Fernandes | Lisbon | Portugal |
| 21 | Madalena | Sampaio | Porto | Portugal |
| 22 | Hannah | Schneider | Berlin | Germany |
| 23 | Fynn | Zimmermann | Frankfurt | Germany |
| 24 | Niklas | Schröder | Berlin | Germany |
| 25 | Camille | Bernard | Paris | France |
| 26 | Dominique | Lefebvre | Paris | France |
| 27 | Marc | Dubois | Lyon | France |
| 28 | Wyatt | Girard | Bordeaux | France |
| 29 | Isabelle | Mercier | Dijon | France |
| 30 | Terhi | Hämäläinen | Helsinki | Finland |
| 31 | Ladislav | Kovács | Budapest | Hungary |
| 32 | Hugh | O'Reilly | Dublin | Ireland |
| 33 | Lucas | Mancini | Rome | Italy |
| 34 | Johannes | Van der Berg | Amsterdam | Netherlands |
| 35 | Stanisław | Wójcik | Warsaw | Poland |
| 36 | Enrique | Muñoz | Madrid | Spain |
| 37 | Joakim | Johansson | Stockholm | Sweden |
| 38 | Emma | Jones | London | United Kingdom |
| 39 | Phil | Hughes | London | United Kingdom |
| 40 | Steve | Murray | Edinburgh | United Kingdom |
| 41 | Mark | Taylor | Sidney | Australia |
| 42 | Diego | Gutiérrez | Buenos Aires | Argentina |
| 43 | Luis | Rojas | Santiago | Chile |
| 44 | Manoj | Pareek | Delhi | India |
| 45 | Puja | Srivastava | Bangalore | India |
Facturas (Invoice) con montos totales entre 10 y 20 USD
query='''
SELECT InvoiceId, CustomerId, Total
FROM Invoice
WHERE Total BETWEEN 10 AND 20;
'''
pd.read_sql(query, conn)
| InvoiceId | CustomerId | Total | |
|---|---|---|---|
| 0 | 5 | 23 | 13.86 |
| 1 | 12 | 2 | 13.86 |
| 2 | 19 | 40 | 13.86 |
| 3 | 26 | 19 | 13.86 |
| 4 | 33 | 57 | 13.86 |
| 5 | 40 | 36 | 13.86 |
| 6 | 47 | 15 | 13.86 |
| 7 | 54 | 53 | 13.86 |
| 8 | 61 | 32 | 13.86 |
| 9 | 68 | 11 | 13.86 |
| 10 | 75 | 49 | 13.86 |
| 11 | 82 | 28 | 13.86 |
| 12 | 88 | 57 | 17.91 |
| 13 | 89 | 7 | 18.86 |
| 14 | 103 | 24 | 15.86 |
| 15 | 110 | 3 | 13.86 |
| 16 | 117 | 41 | 13.86 |
| 17 | 124 | 20 | 13.86 |
| 18 | 131 | 58 | 13.86 |
| 19 | 138 | 37 | 13.86 |
| 20 | 145 | 16 | 13.86 |
| 21 | 152 | 54 | 13.86 |
| 22 | 159 | 33 | 13.86 |
| 23 | 166 | 12 | 13.86 |
| 24 | 173 | 50 | 13.86 |
| 25 | 180 | 29 | 13.86 |
| 26 | 187 | 8 | 13.86 |
| 27 | 193 | 37 | 14.91 |
| 28 | 201 | 25 | 18.86 |
| 29 | 208 | 4 | 15.86 |
| 30 | 215 | 42 | 13.86 |
| 31 | 222 | 21 | 13.86 |
| 32 | 229 | 59 | 13.86 |
| 33 | 236 | 38 | 13.86 |
| 34 | 243 | 17 | 13.86 |
| 35 | 250 | 55 | 13.86 |
| 36 | 257 | 34 | 13.86 |
| 37 | 264 | 13 | 13.86 |
| 38 | 271 | 51 | 13.86 |
| 39 | 278 | 30 | 13.86 |
| 40 | 285 | 9 | 13.86 |
| 41 | 292 | 47 | 13.86 |
| 42 | 298 | 17 | 10.91 |
| 43 | 306 | 5 | 16.86 |
| 44 | 311 | 28 | 11.94 |
| 45 | 312 | 34 | 10.91 |
| 46 | 313 | 43 | 16.86 |
| 47 | 320 | 22 | 13.86 |
| 48 | 327 | 1 | 13.86 |
| 49 | 334 | 39 | 13.86 |
| 50 | 341 | 18 | 13.86 |
| 51 | 348 | 56 | 13.86 |
| 52 | 355 | 35 | 13.86 |
| 53 | 362 | 14 | 13.86 |
| 54 | 369 | 52 | 13.86 |
| 55 | 376 | 31 | 13.86 |
| 56 | 383 | 10 | 13.86 |
| 57 | 390 | 48 | 13.86 |
| 58 | 397 | 27 | 13.86 |
| 59 | 411 | 44 | 13.86 |
FUNCIONES DE AGREGACION#
COUNT( name ) AS othernameCOUNT(DISTINCT name) AS othernameSUM( name) AS othernameAVG(name) AS othernameMIN(name) AS othernameMAX(name) AS othername
# Contar el total de clientes en la tabla Customer
query='''
SELECT COUNT(CustomerId) AS TotalClientes
FROM Customer;
'''
pd.read_sql(query, conn)
| TotalClientes | |
|---|---|
| 0 | 59 |
# Contar el total de países en la tabla Customer
query='''
SELECT COUNT(Country) AS TotalPaises
FROM Customer;
'''
pd.read_sql(query, conn)
| TotalPaises | |
|---|---|
| 0 | 59 |
# Contar el total de países distintos/unicos en la tabla Customer
query='''
SELECT COUNT(DISTINCT Country) AS TotalPaises
FROM Customer;
'''
pd.read_sql(query, conn)
| TotalPaises | |
|---|---|
| 0 | 24 |
# Sumar el total de ventas en la tabla Invoice
query='''
SELECT SUM(Total) AS TotalVentas
FROM Invoice;
'''
pd.read_sql(query, conn)
| TotalVentas | |
|---|---|
| 0 | 2328.6 |
# Calcular el promedio de ventas entre 2009 y 2011
query='''
SELECT AVG(Total) AS PromedioVentas
FROM Invoice
WHERE InvoiceDate BETWEEN '2009-01-01' AND '2011-12-31';
'''
pd.read_sql(query, conn)
| PromedioVentas | |
|---|---|
| 0 | None |
# Encontrar la factura mínima y máxima en la tabla Invoice
query='''
SELECT MIN(Total) AS FacturaMinima,
MAX(Total) AS FacturaMaxima
FROM Invoice;
'''
pd.read_sql(query, conn)
| FacturaMinima | FacturaMaxima | |
|---|---|---|
| 0 | 0.99 | 25.86 |
# Calcular la diferencia entre la factura máxima y mínima en Canadá
query='''
SELECT
MAX(Total) - MIN(Total) AS DiferenciaTotal
FROM
Invoice
WHERE
BillingCountry = 'Canada';
'''
pd.read_sql(query, conn)
| DiferenciaTotal | |
|---|---|
| 0 | 12.87 |
GROUP BY - ORDER BY#
GROUP BY agrupa filas que tienen valores iguales en una o varias columnas, para que puedas aplicar funciones de agregación (como COUNT(), SUM(), AVG(), etc.) a cada grupo.
⚠️ Reglas importantes
Todas las columnas en el SELECT deben estar:
O bien en el GROUP BY
O dentro de una función de agregación (COUNT, SUM, etc.)
Si no se cumple lo anterior, obtendrás un error de SQL.⚠️
# Promedio de duración por género y promedio de precio por unidad
query='''
SELECT
GenreId AS IDGenero,
AVG(Milliseconds)/1000 AS Duracion_Promedio,
AVG(UnitPrice) AS Precio_Promedio
FROM Track
GROUP BY GenreId
ORDER BY Precio_Promedio DESC
'''
pd.read_sql(query,conn)
| IDGenero | Duracion_Promedio | Precio_Promedio | |
|---|---|---|---|
| 0 | 18 | 2625.549077 | 1.99 |
| 1 | 19 | 2145.041022 | 1.99 |
| 2 | 20 | 2911.783038 | 1.99 |
| 3 | 21 | 2575.283781 | 1.99 |
| 4 | 22 | 1585.263706 | 1.99 |
| 5 | 7 | 232.859263 | 0.99 |
| 6 | 24 | 293.867568 | 0.99 |
| 7 | 1 | 283.910043 | 0.99 |
| 8 | 3 | 309.749444 | 0.99 |
| 9 | 4 | 234.353849 | 0.99 |
| 10 | 6 | 270.359778 | 0.99 |
| 11 | 8 | 247.177759 | 0.99 |
| 12 | 10 | 244.370884 | 0.99 |
| 13 | 11 | 219.590000 | 0.99 |
| 14 | 13 | 297.452929 | 0.99 |
| 15 | 14 | 220.066852 | 0.99 |
| 16 | 15 | 302.985800 | 0.99 |
| 17 | 16 | 224.923821 | 0.99 |
| 18 | 17 | 178.176286 | 0.99 |
| 19 | 23 | 264.058525 | 0.99 |
| 20 | 25 | 174.813000 | 0.99 |
| 21 | 2 | 291.755377 | 0.99 |
| 22 | 5 | 134.643500 | 0.99 |
| 23 | 9 | 229.034104 | 0.99 |
| 24 | 12 | 189.164208 | 0.99 |
#Cantidad de canciones por Género y promedio en segundos
query='''
SELECT
GenreId AS IDGenero,
Composer AS Compositor,
COUNT(*) AS total_canciones,
AVG(Milliseconds)/1000 AS Duracion_Promedio
FROM Track
WHERE
Composer IS NOT NULL
GROUP BY
GenreId,
Composer
ORDER BY
total_canciones DESC,
Compositor ASC
'''
pd.read_sql(query,conn)
| IDGenero | Compositor | total_canciones | Duracion_Promedio | |
|---|---|---|---|---|
| 0 | 1 | U2 | 44 | 256.177636 |
| 1 | 3 | Steve Harris | 36 | 344.181694 |
| 2 | 1 | Jagger/Richards | 35 | 247.633657 |
| 3 | 4 | Billy Corgan | 31 | 255.243645 |
| 4 | 1 | Kurt Cobain | 26 | 193.482346 |
| ... | ... | ... | ... | ... |
| 891 | 1 | ian paice/jon lord | 1 | 356.963000 |
| 892 | 12 | jim croce | 1 | 169.900000 |
| 893 | 12 | lorenz hart/richard rodgers | 1 | 184.111000 |
| 894 | 12 | orlando murden/ronald miller | 1 | 171.154000 |
| 895 | 12 | rod mckuen | 1 | 203.964000 |
896 rows × 4 columns
#Cantidad de canciones por Género y promedio en segundos para autores desconocidos
query='''
SELECT
GenreId AS IDGenero,
Composer AS Compositor,
COUNT(*) AS total_canciones,
AVG(Milliseconds)/1000 AS Duracion_Promedio
FROM Track
WHERE
Composer IS NULL
GROUP BY
GenreId,
Composer
ORDER BY
total_canciones DESC,
Compositor ASC
'''
pd.read_sql(query,conn)
| IDGenero | Compositor | total_canciones | Duracion_Promedio | |
|---|---|---|---|---|
| 0 | 7 | None | 309 | 236.063628 |
| 1 | 1 | None | 167 | 300.341497 |
| 2 | 19 | None | 93 | 2145.041022 |
| 3 | 21 | None | 64 | 2575.283781 |
| 4 | 2 | None | 51 | 234.459255 |
| 5 | 3 | None | 44 | 298.544614 |
| 6 | 4 | None | 31 | 222.648645 |
| 7 | 8 | None | 27 | 257.777741 |
| 8 | 9 | None | 26 | 227.256077 |
| 9 | 20 | None | 26 | 2911.783038 |
| 10 | 23 | None | 26 | 279.613154 |
| 11 | 15 | None | 17 | 260.520176 |
| 12 | 22 | None | 17 | 1585.263706 |
| 13 | 10 | None | 16 | 274.587312 |
| 14 | 17 | None | 16 | 185.444375 |
| 15 | 11 | None | 15 | 219.590000 |
| 16 | 18 | None | 13 | 2625.549077 |
| 17 | 14 | None | 10 | 201.638400 |
| 18 | 24 | None | 6 | 227.417333 |
| 19 | 13 | None | 3 | 234.753333 |
¿Cuál es el total de canciones cuyo autor es desconocido?
No se usa GROUP BY porque queremos una sola fila con la suma total de todas las canciones.
No hay necesidad de agrupar: el resultado es global.
# Aqui no se requiere Group by
query='''
SELECT
COUNT(TrackId) AS total_canciones_desconocidas
FROM Track
WHERE
Composer IS NULL
'''
pd.read_sql(query,conn)
| total_canciones_desconocidas | |
|---|---|
| 0 | 977 |
WHERE VS HAVING#
|
|
|---|---|
Filtra antes de agrupar |
Filtra después de agrupar |
Se usa con columnas |
Se usa con funciones de agregación |
Afecta qué filas se agrupan |
Afecta qué grupos se muestran |
🧠 Pensamiento clave:
Usa WHERE para filtrar filas individuales.
Usa HAVING para filtrar grupos después de aplicar GROUP BY.
# Canciones de más de 3 minutos
query='''
SELECT Name, Milliseconds
FROM Track
WHERE Milliseconds > 180000;
'''
pd.read_sql(query,conn)
| Name | Milliseconds | |
|---|---|---|
| 0 | For Those About To Rock (We Salute You) | 343719 |
| 1 | Balls to the Wall | 342562 |
| 2 | Fast As a Shark | 230619 |
| 3 | Restless and Wild | 252051 |
| 4 | Princess of the Dawn | 375418 |
| ... | ... | ... |
| 3018 | Erlkonig, D.328 | 261849 |
| 3019 | Concerto for Violin, Strings and Continuo in G... | 493573 |
| 3020 | Pini Di Roma (Pinien Von Rom) \ I Pini Della V... | 286741 |
| 3021 | Quintet for Horn, Violin, 2 Violas, and Cello ... | 221331 |
| 3022 | Koyaanisqatsi | 206005 |
3023 rows × 2 columns
#Facturas mayores a $10
query='''
SELECT InvoiceId, Total
FROM invoice
WHERE Total > 10
ORDER BY Total DESC
LIMIT 15
'''
pd.read_sql(query,conn)
| InvoiceId | Total | |
|---|---|---|
| 0 | 404 | 25.86 |
| 1 | 299 | 23.86 |
| 2 | 96 | 21.86 |
| 3 | 194 | 21.86 |
| 4 | 89 | 18.86 |
| 5 | 201 | 18.86 |
| 6 | 88 | 17.91 |
| 7 | 306 | 16.86 |
| 8 | 313 | 16.86 |
| 9 | 103 | 15.86 |
| 10 | 208 | 15.86 |
| 11 | 193 | 14.91 |
| 12 | 5 | 13.86 |
| 13 | 12 | 13.86 |
| 14 | 19 | 13.86 |
#Géneros con más de 100 canciones
query='''
SELECT GenreId,
COUNT(*) AS total
FROM Track
GROUP BY GenreId
HAVING COUNT(*) > 50
ORDER BY total DESC
LIMIT 5
'''
pd.read_sql(query,conn)
| GenreId | total | |
|---|---|---|
| 0 | 1 | 1297 |
| 1 | 7 | 579 |
| 2 | 3 | 374 |
| 3 | 4 | 332 |
| 4 | 2 | 130 |
#Clientes que han gastado más de $50
query='''
SELECT CustomerId,
SUM(Total) AS total_gastado
FROM Invoice
GROUP BY CustomerId
HAVING total_gastado > 12
ORDER BY total_gastado DESC
LIMIT 8
'''
pd.read_sql(query,conn)
| CustomerId | total_gastado | |
|---|---|---|
| 0 | 6 | 49.62 |
| 1 | 26 | 47.62 |
| 2 | 57 | 46.62 |
| 3 | 45 | 45.62 |
| 4 | 46 | 45.62 |
| 5 | 24 | 43.62 |
| 6 | 28 | 43.62 |
| 7 | 37 | 43.62 |
CASE - WHEN#
CASE WHEN te permite hacer condiciones dentro de una consulta SQL, como un if…else.
Sirve para crear nuevas columnas calculadas o categorizadas según reglas lógicas.
#Clasificar duración de canciones
query='''
SELECT
Name,
Milliseconds,
CASE
WHEN Milliseconds < 180000 THEN 'Corta'
WHEN Milliseconds BETWEEN 180000 AND 300000 THEN 'Media'
ELSE 'Larga'
END AS duracion_clasificada
FROM Track
ORDER BY duracion_clasificada
'''
pd.read_sql(query,conn)
| Name | Milliseconds | duracion_clasificada | |
|---|---|---|---|
| 0 | Right Through You | 176117 | Corta |
| 1 | We Die Young | 152084 | Corta |
| 2 | Samba De Uma Nota Só (One Note Samba) | 137273 | Corta |
| 3 | Por Causa De Você | 169900 | Corta |
| 4 | Fotografia | 129227 | Corta |
| ... | ... | ... | ... |
| 3498 | 24 Caprices, Op. 1, No. 24, for Solo Violin, i... | 265541 | Media |
| 3499 | Erlkonig, D.328 | 261849 | Media |
| 3500 | Pini Di Roma (Pinien Von Rom) \ I Pini Della V... | 286741 | Media |
| 3501 | Quintet for Horn, Violin, 2 Violas, and Cello ... | 221331 | Media |
| 3502 | Koyaanisqatsi | 206005 | Media |
3503 rows × 3 columns
🧩 Ejercicio 3#
Crea una consulta que clasifique los géneros musicales por número de canciones:
Pocossi tienen menos de 50 cancionesNormalessi tienen entre 50 y 100Popularessi tienen más de 100
query='''
SELECT
GenreId,
COUNT(GenreID) AS total_canciones,
CASE
WHEN COUNT(GenreID) < 50 THEN 'Pocos'
WHEN COUNT(GenreID) BETWEEN 50 AND 100 THEN 'Normales'
ELSE 'Populares'
END AS clasificacion
FROM Track
GROUP BY GenreId
'''
pd.read_sql(query,conn)
| GenreId | total_canciones | clasificacion | |
|---|---|---|---|
| 0 | 1 | 1297 | Populares |
| 1 | 2 | 130 | Populares |
| 2 | 3 | 374 | Populares |
| 3 | 4 | 332 | Populares |
| 4 | 5 | 12 | Pocos |
| 5 | 6 | 81 | Normales |
| 6 | 7 | 579 | Populares |
| 7 | 8 | 58 | Normales |
| 8 | 9 | 48 | Pocos |
| 9 | 10 | 43 | Pocos |
| 10 | 11 | 15 | Pocos |
| 11 | 12 | 24 | Pocos |
| 12 | 13 | 28 | Pocos |
| 13 | 14 | 61 | Normales |
| 14 | 15 | 30 | Pocos |
| 15 | 16 | 28 | Pocos |
| 16 | 17 | 35 | Pocos |
| 17 | 18 | 13 | Pocos |
| 18 | 19 | 93 | Normales |
| 19 | 20 | 26 | Pocos |
| 20 | 21 | 64 | Normales |
| 21 | 22 | 17 | Pocos |
| 22 | 23 | 40 | Pocos |
| 23 | 24 | 74 | Normales |
| 24 | 25 | 1 | Pocos |
¿Cuáles son los países con más de 5 facturas emitidas, ordenalos de mayor a menor?
query='''
SELECT
BillingCountry,
COUNT(*) AS total_facturas
FROM invoice
GROUP BY BillingCountry
HAVING COUNT(*) > 5
ORDER BY total_facturas DESC
'''
pd.read_sql(query,conn)
| BillingCountry | total_facturas | |
|---|---|---|
| 0 | USA | 91 |
| 1 | Canada | 56 |
| 2 | France | 35 |
| 3 | Brazil | 35 |
| 4 | Germany | 28 |
| 5 | United Kingdom | 21 |
| 6 | Portugal | 14 |
| 7 | Czech Republic | 14 |
| 8 | India | 13 |
| 9 | Sweden | 7 |
| 10 | Spain | 7 |
| 11 | Poland | 7 |
| 12 | Norway | 7 |
| 13 | Netherlands | 7 |
| 14 | Italy | 7 |
| 15 | Ireland | 7 |
| 16 | Hungary | 7 |
| 17 | Finland | 7 |
| 18 | Denmark | 7 |
| 19 | Chile | 7 |
| 20 | Belgium | 7 |
| 21 | Austria | 7 |
| 22 | Australia | 7 |
| 23 | Argentina | 7 |
Clasifica a los empleados por su cargo Muestra los empleados, su cargo (Title) y una etiqueta basada en su cargo:
“Soporte” si es Support Agent
“Ventas” si contiene la palabra Sales
“Otro” para los demás
Solo muestra aquellos cuyo título no sea “IT Manager”, ordenados alfabéticamente por la etiqueta.
query='''
SELECT
FirstName AS Nombre,
LastName AS Apellido,
Title AS Cargo,
CASE
WHEN Title = 'Support Agent' THEN 'Soporte'
WHEN Title LIKE '%Sales%' THEN 'Ventas'
ELSE 'Otro'
END AS rol_etiqueta
FROM employee
WHERE Title != 'IT Manager'
ORDER BY rol_etiqueta
'''
pd.read_sql(query,conn)
| Nombre | Apellido | Cargo | rol_etiqueta | |
|---|---|---|---|---|
| 0 | Andrew | Adams | General Manager | Otro |
| 1 | Robert | King | IT Staff | Otro |
| 2 | Laura | Callahan | IT Staff | Otro |
| 3 | Nancy | Edwards | Sales Manager | Ventas |
| 4 | Jane | Peacock | Sales Support Agent | Ventas |
| 5 | Margaret | Park | Sales Support Agent | Ventas |
| 6 | Steve | Johnson | Sales Support Agent | Ventas |
TIPOS DE DATOS: CONVERSIONES#
Los más comunes son:
INTEGER para números enteros,
REAL o FLOAT para números decimales
TEXT para cadenas de caracteres (como nombres o descripciones)
DATE para fechas.
query='''
SELECT CAST('123' AS INTEGER) AS numero;
'''
pd.read_sql(query, conn)
| numero | |
|---|---|
| 0 | 123 |
query='''
SELECT CAST(456 AS TEXT) AS texto;
'''
pd.read_sql(query, conn)
| texto | |
|---|---|
| 0 | 456 |
query='''
SELECT DATE('2023-06-26') AS fecha_valida;
'''
pd.read_sql(query, conn)
| fecha_valida | |
|---|---|
| 0 | 2023-06-26 |
Cierre#
Resumen de aprendizajes clave:
Navegamos un esquema relacional e identificamos PK/FK.
Practicamos
SELECT,WHERE,ORDER BYyGROUP BY, junto con agregaciones (COUNT,SUM,AVG)Aplicamos filtros con
HAVINGy gestionamos resultados conLIMIT.Q&A y próximos pasos.
Recursos adicionales#
sqliteonline.com - Entorno online para practicar SQL con bases de datos SQLite
Sesión Práctica#
🧪 Taller práctico: Analítica de negocio con SQL (DB Chinook)#
Objetivo: practicar GROUP BY, funciones de agregación, HAVING, BETWEEN, CASE WHEN**
Tablas que vamos a usar:
invoicesinvoice_items(oInvoiceLine, según tu versión)customerstracks
1️⃣ Volumen de facturas por país#
Pregunta de negocio:
¿Qué países generan más facturas en la tienda?
Instrucciones:
Usa la tabla
invoices.Cuenta cuántas facturas hay por
BillingCountry.Ordena de mayor a menor número de facturas.
2️⃣ Ingreso total por país#
Pregunta: ¿Qué países generan más ingresos totales?
3️⃣ Ticket promedio por país#
Pregunta: ¿Qué países tienen el monto promedio más alto por factura?
4️⃣ Países con volumen significativo de facturas#
Pregunta: ¿Qué países tienen más de 20 facturas?
5️⃣ Ingresos por país en un rango de fechas (BETWEEN)#
Pregunta: ¿Cuál fue el ingreso total por país durante el año 2010?
6️⃣ Número de clientes por país#
Pregunta: ¿Qué países tienen más de 10 clientes?
7️⃣ Clasificación de facturas por monto (CASE WHEN)#
Pregunta: ¿Cómo se distribuyen las facturas entre pequeñas, medianas y grandes?
Pequeña: < 5
Mediana: BETWEEN 5 AND 15
Grande: > 15
8️⃣ Cantidad total de ítems vendidos por factura#
Pregunta: ¿Qué facturas tienen más unidades vendidas?
9️⃣ Facturas con alto volumen de unidades (HAVING)#
Pregunta: ¿Qué facturas superan 20 unidades vendidas?
🔟 Duración total y promedio por tipo de medio#
Pregunta: ¿Qué tipo de medio tiene mayor duración total de pistas?
Siguientes Pasos#
Próxima semana: JOINs, CTEs y subconsultas para KPIs financieros: ingresos por periodo, margen por categoría y retención.
Participación continua: asistir a Co-Learning y a Sprint Focus, y usar los canales de Discord para hacer preguntas.
Recordatorios: la grabación y recursos utilizados, se comparten al finalizar la sesión; en caso de necesitar apoyo adicional, agenda un 1:1.